What are we modeling? Using predictive fit to inform effect metric choice in meta-analysis
2025-10-09
Class attendance and college grades
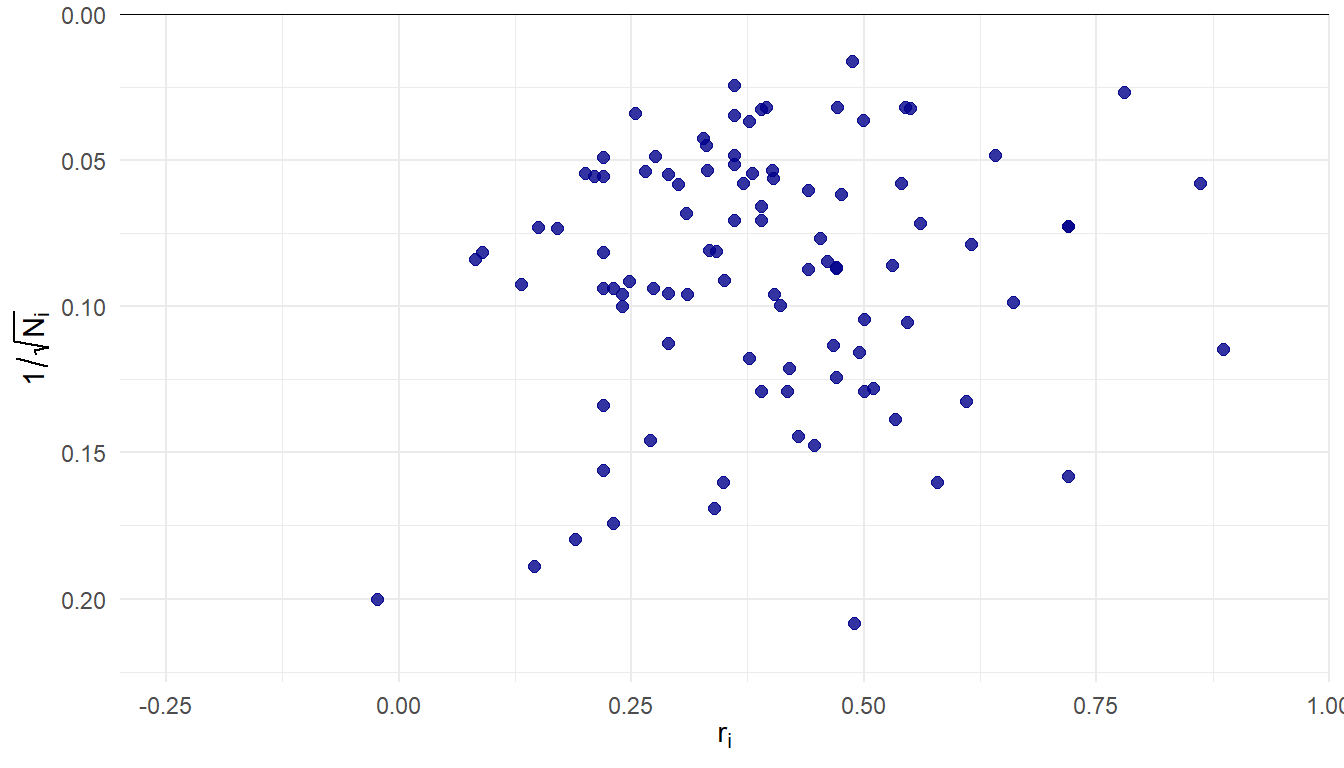
Credé and colleagues19 reported a systematic review and meta-analysis of studies on association between class attendance and grades / GPA in college.
99 correlation estimates, samples ranging from \(N_i\) = 23 to 3900 (median = 151, IQR = 76-335).
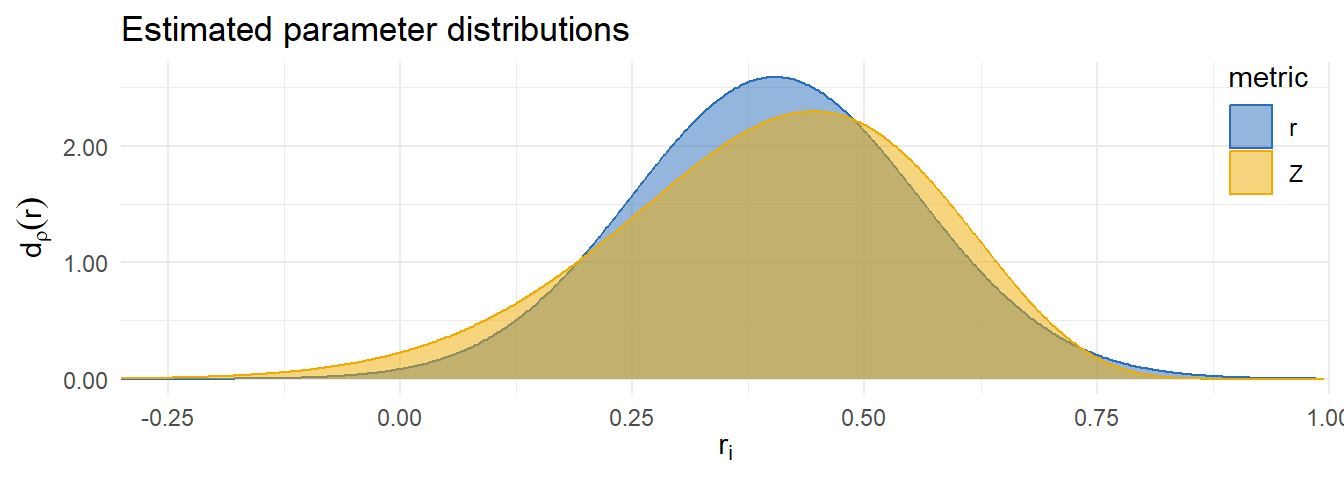
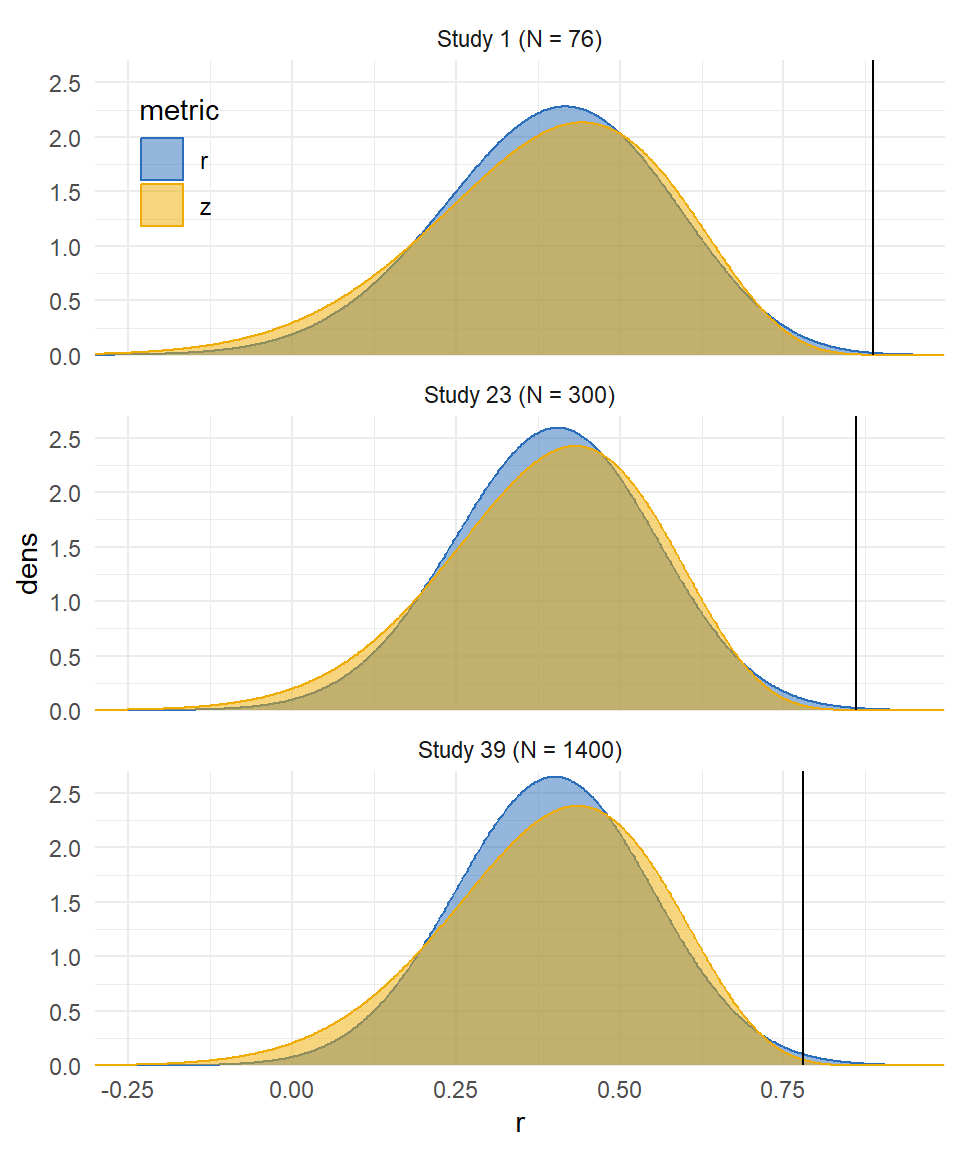
Metric comparison
| Metric | Est. | 95% CI | 80% PI | LPD | SE |
|---|---|---|---|---|---|
| r | 0.40 | 0.37-0.44 | 0.20-0.60 | 0.34 | 0.09 |
| z | 0.41 | 0.37-0.45 | 0.16-0.61 | 0.22 | 0.12 |
| Difference | 0.12 | 0.05 |
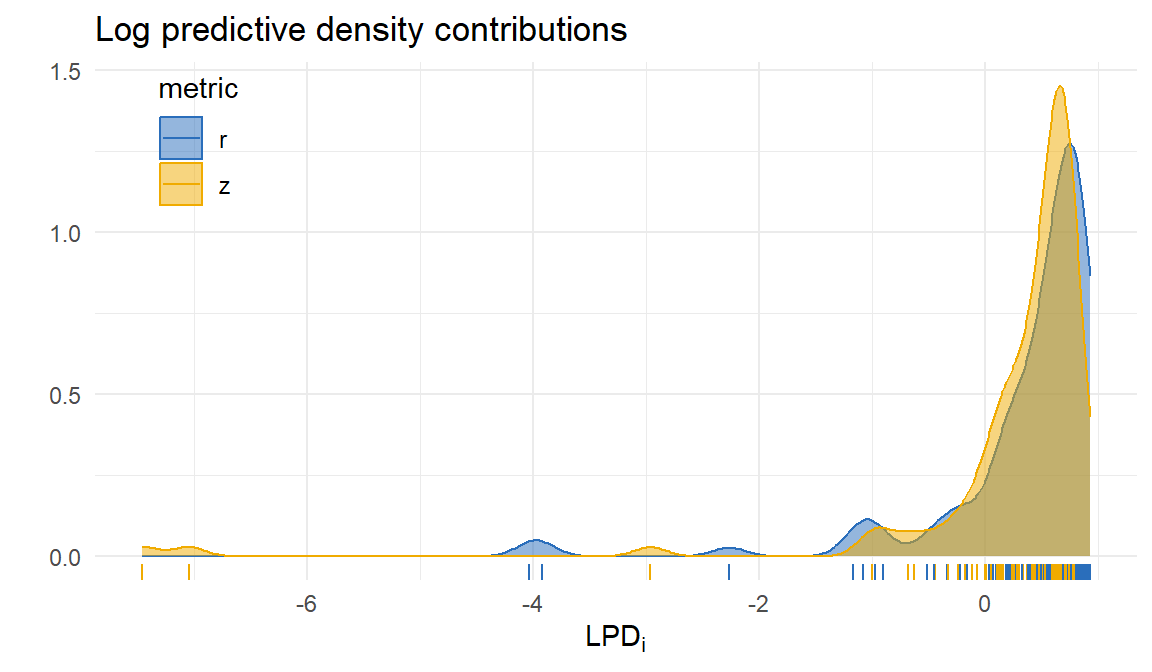
Outliers
Reliability generalization of MIBS
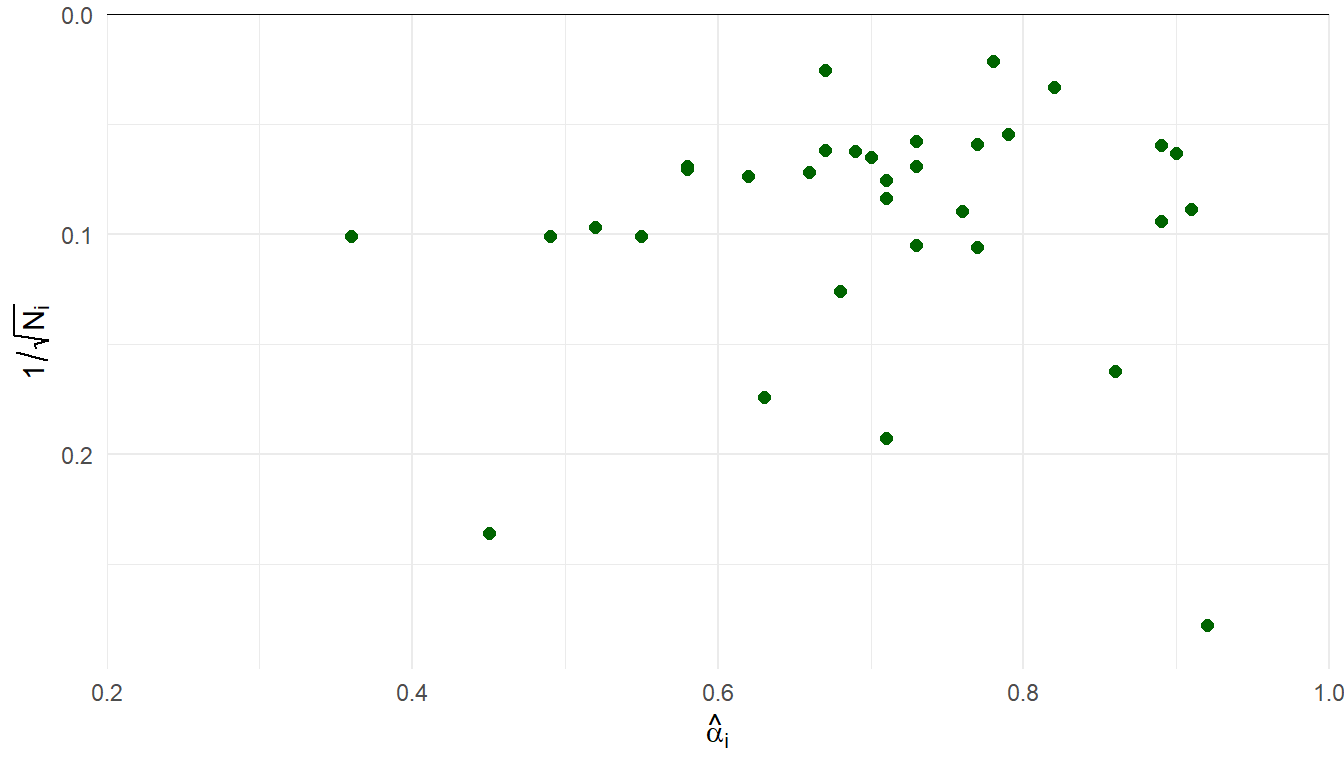
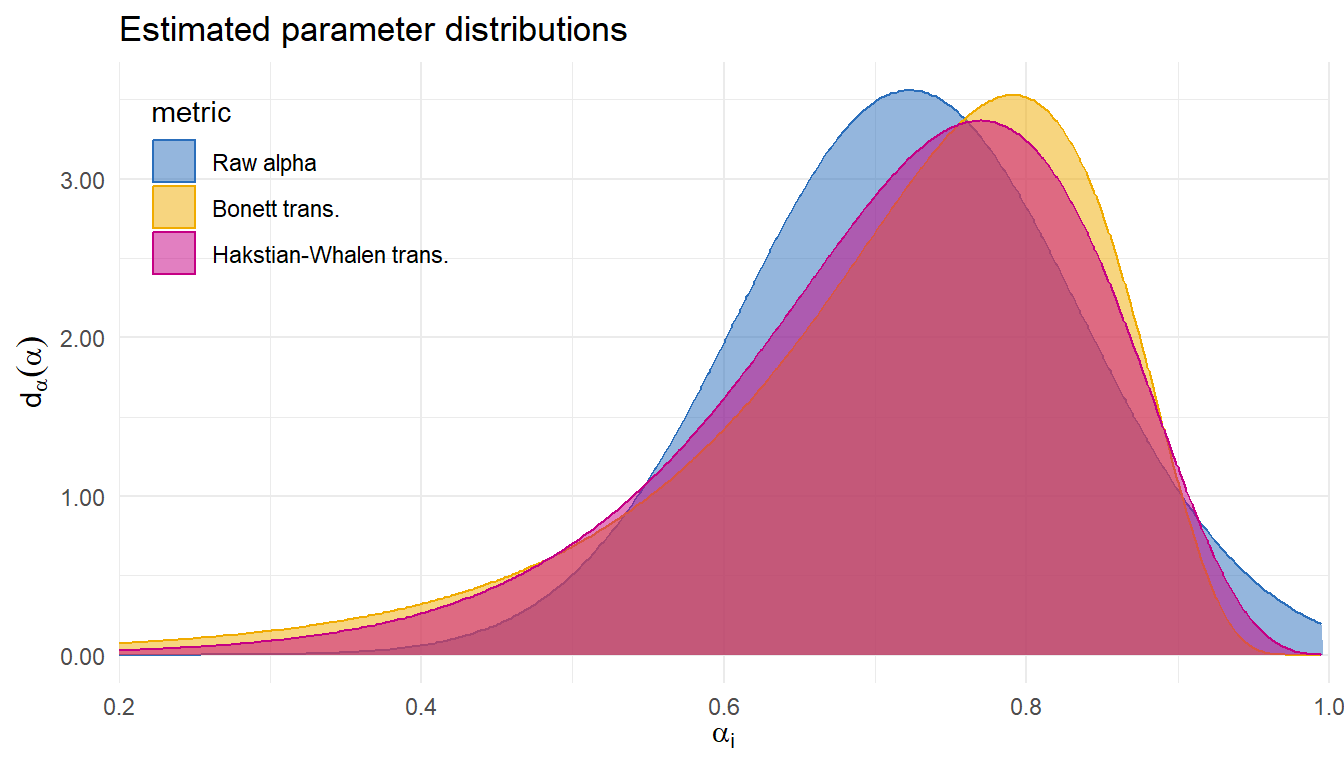
Demir and colleagues20 gathered 33 estimates of internal consistency (Cronbach \(\alpha\)) of the Mother-to-Infant Bonding Scale.
Sample sizes ranging from \(N_i\) = 13 to 2251 (median = 177, IQR = 98-260).
| Metric | Est. | 95% CI | 80% PI | LPD | SE |
|---|---|---|---|---|---|
| Raw alpha | 0.72 | 0.68-0.76 | 0.58-0.87 | 0.57 | 0.16 |
| Bonett trans. | 0.74 | 0.69-0.78 | 0.51-0.86 | 0.53 | 0.12 |
| Hakstian-Whalen trans. | 0.73 | 0.68-0.77 | 0.53-0.86 | 0.58 | 0.11 |
Incidence of olfactory loss in COVID-19 patients
Hannum and colleagues21 compiled data on rates of olfactory loss across 35 studies of COVID-19 patients.
Sample sizes ranging from \(N_i\) = 15 to 7178 (median = 95, IQR = 56.5 - 267.5).
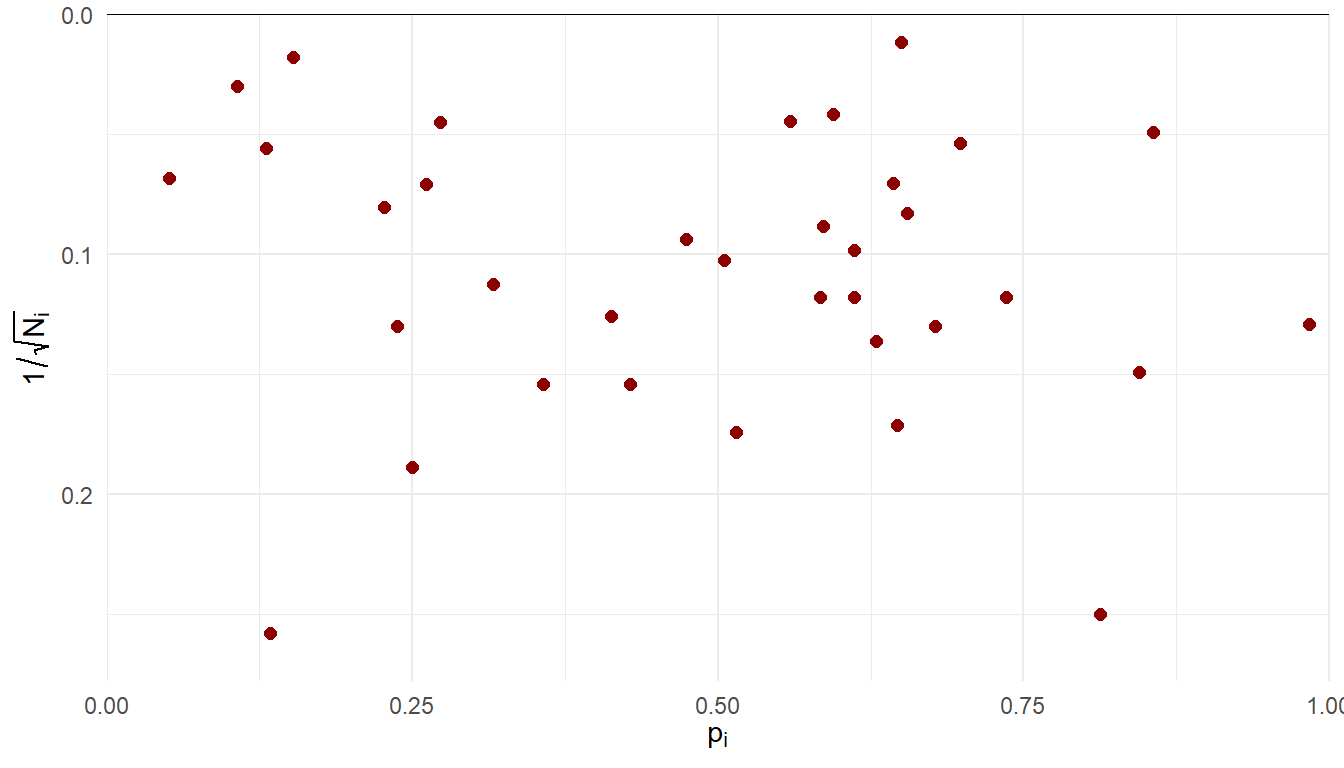
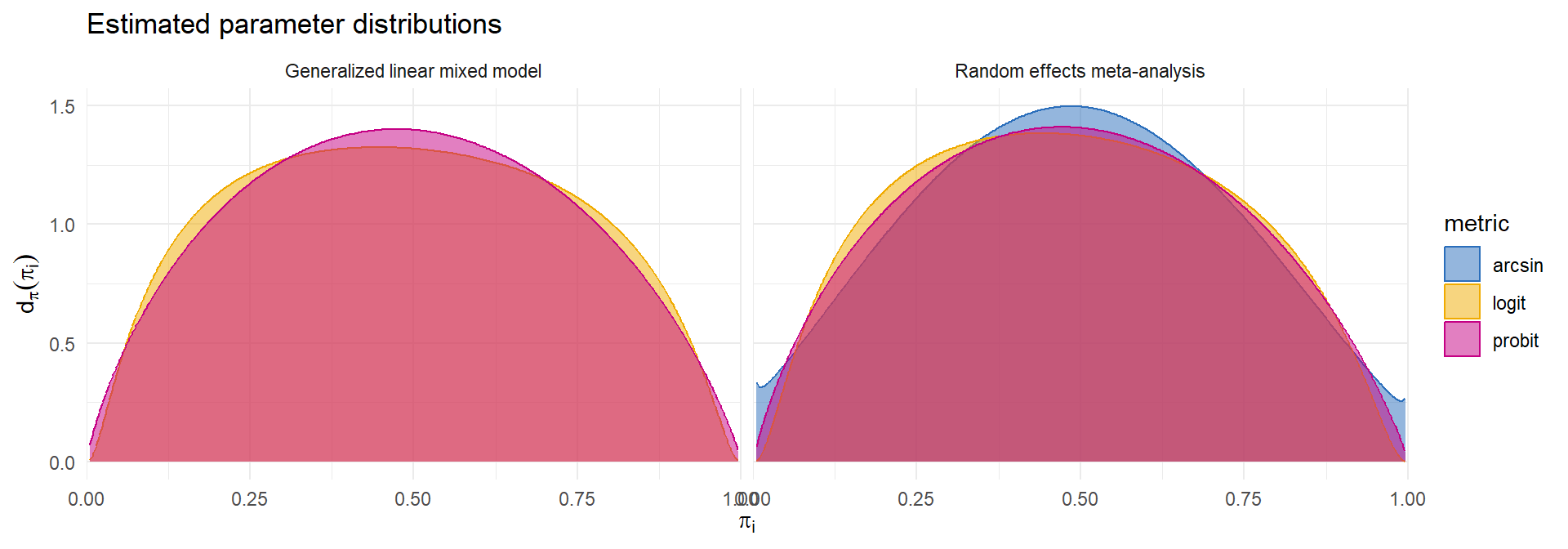
Many different transformations of \(p_i\) are used as effect size measures (identity, logit, probit, arcsin-square-root, Freeman-Tukey).
Could use conventional random effects model or generalized linear mixed model.
- Which predictive model to use?
\[ \begin{aligned} g(p_i) &\dot{\sim} \ N\left(g(\pi_i), \ \frac{h(\pi_i)}{N_i}\right) \qquad & N_i p_i &\sim \ Binom\left(N_i, \ \pi_i\right)\\ g(\pi_i) &\sim \ N\left(\mu_g, \ \tau_g^2\right) \qquad & g(\pi_i) &\sim \ N\left(\mu_g, \ \tau_g^2\right) \end{aligned} \]
Incidence of olfactory loss in COVID-19 patients
| Normal | Binomial | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Metric | Est. | 95% CI | 80% PI | LPD | SE | LPD | SE |
| RE | logit | 0.48 | 0.38-0.58 | 0.17-0.81 | -5.10 | 0.36 | -5.11 | 0.36 |
| RE | probit | 0.49 | 0.39-0.58 | 0.17-0.81 | -5.18 | 0.40 | -5.18 | 0.40 |
| RE | arcsin | 0.49 | 0.40-0.58 | 0.17-0.81 | -4.96 | 0.32 | -4.96 | 0.32 |
| GLMM | logit | 0.48 | 0.38-0.59 | 0.16-0.82 | -5.43 | 0.55 | ||
| GLMM | probit | 0.49 | 0.39-0.58 | 0.17-0.82 | -5.24 | 0.43 | ||
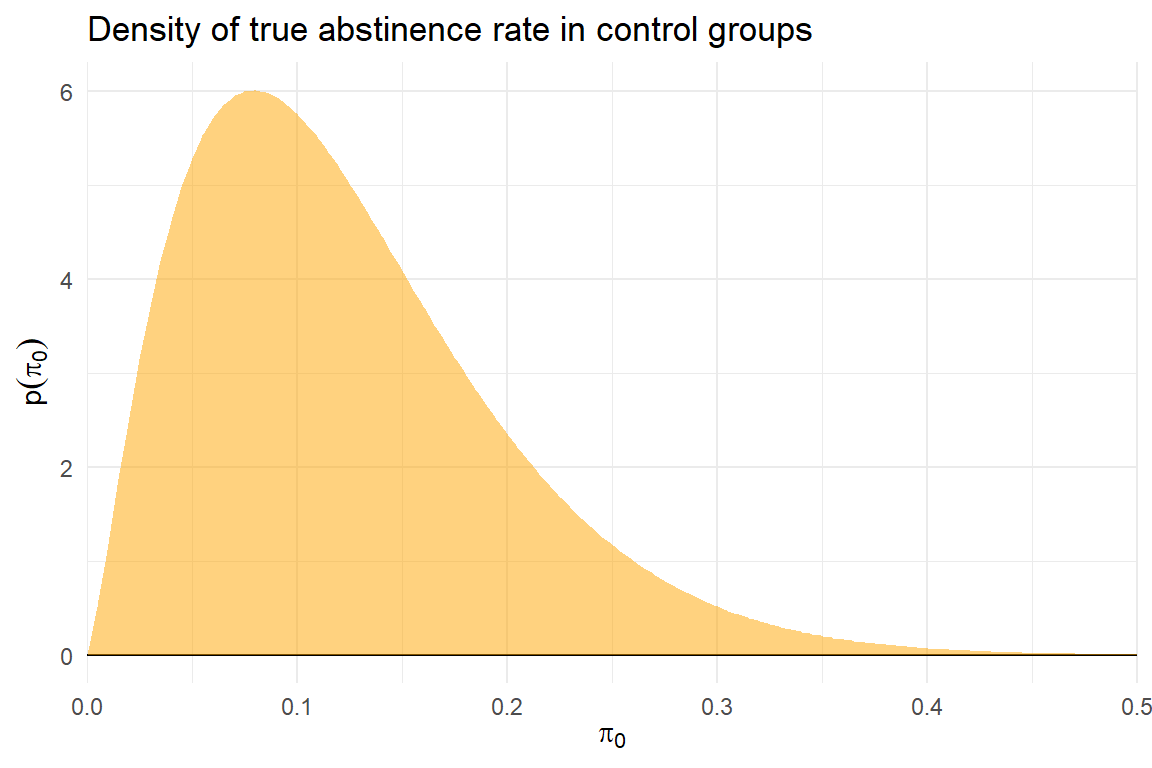
Effectiveness of nicotine replacement therapy
Cochrane Systematic Review of effects of nicotine replacement therapy vs. control on smoking cessation, defined as abstinence at 6+ month follow-up22.
Sample sizes ranging from \(N_i\) = 36 to 5290 (median = 240.5, IQR = 153.5 - 428.5).
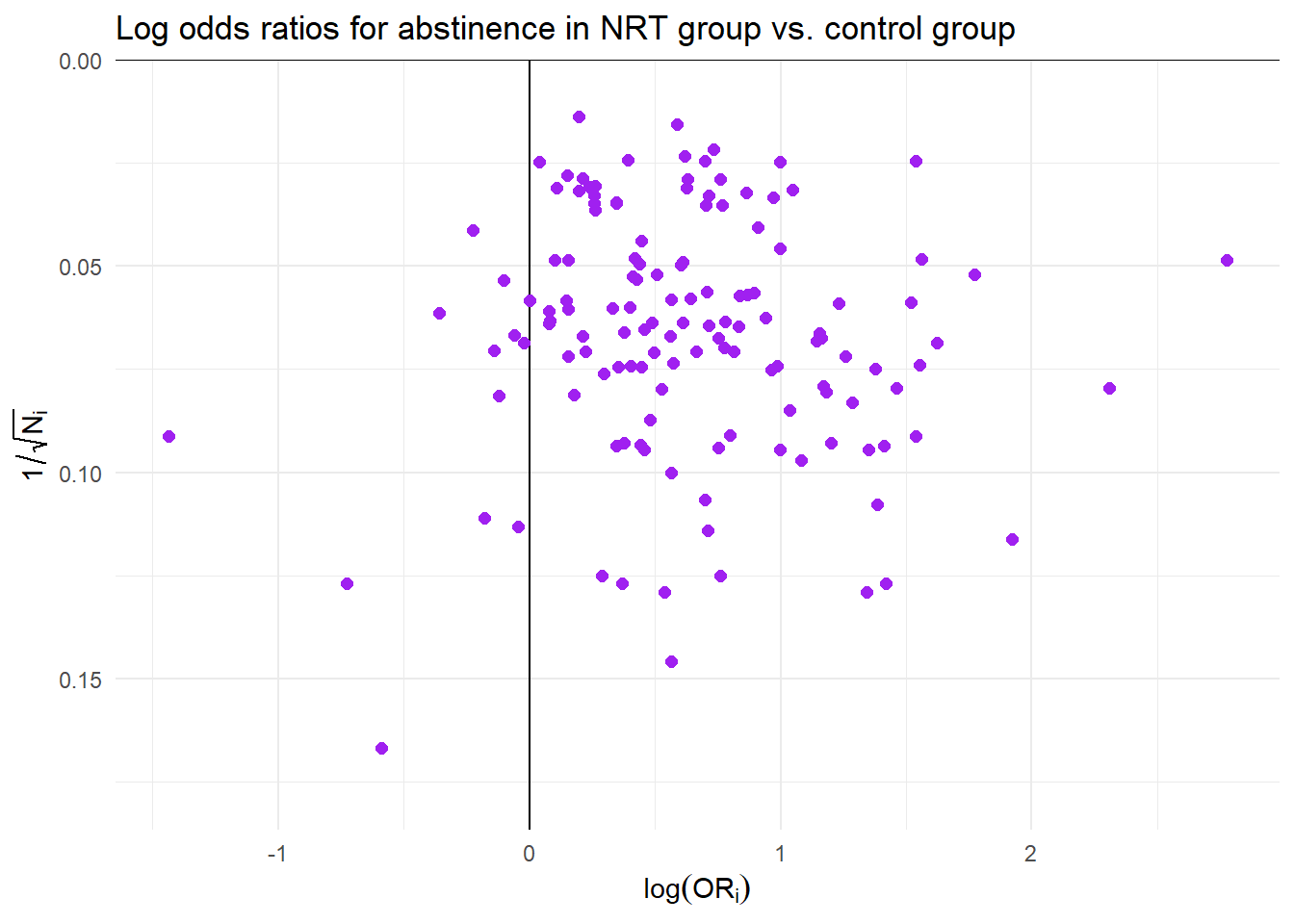
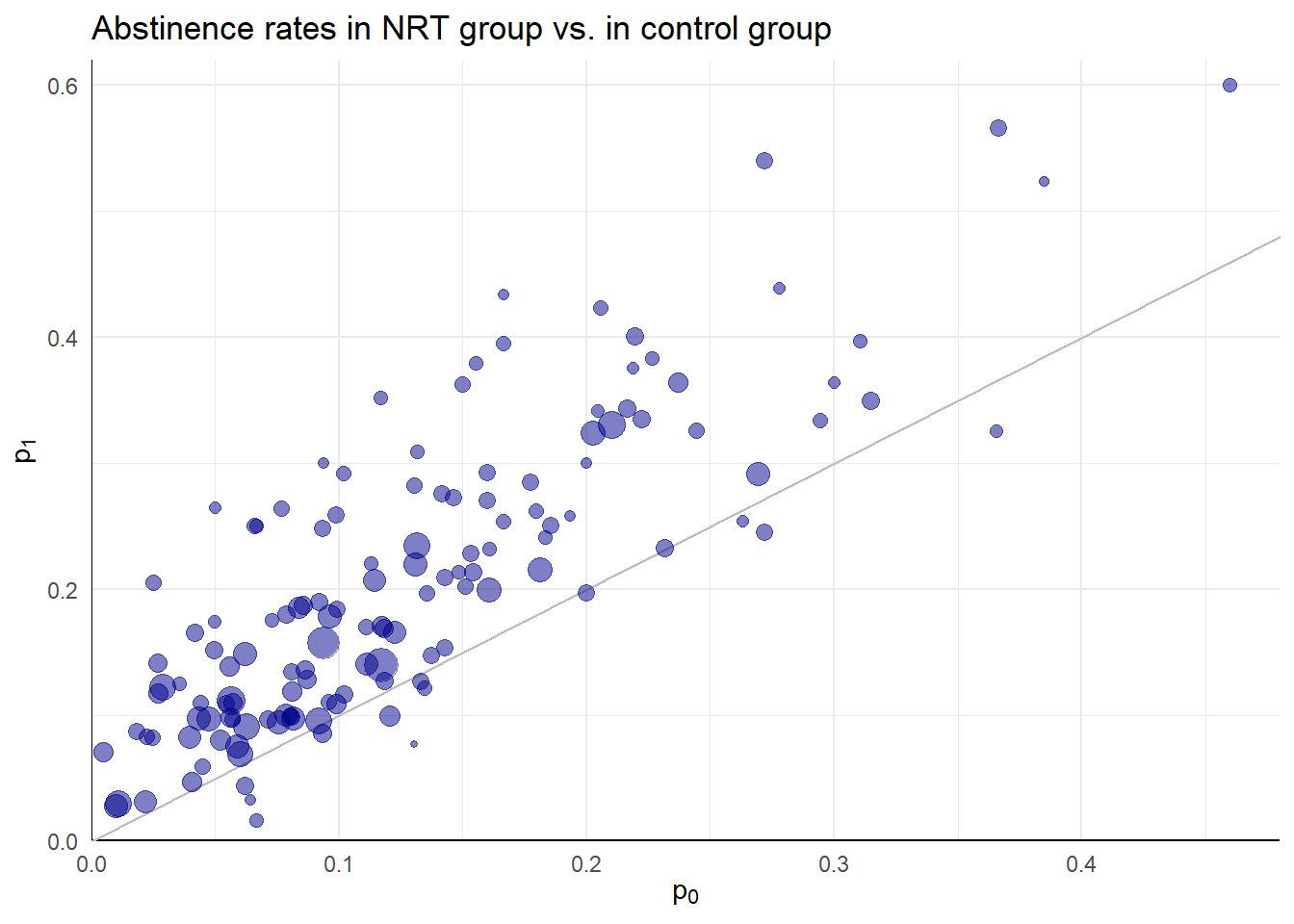
Random effects meta-analysis
- Difference ES metrics suggest very different implications and different heterogeneity
| Metric | Est | 95% CI | 80% PI | I2 |
|---|---|---|---|---|
| Risk difference | 0.06 | 0.05-0.07 | 0.02-0.11 | 63.50 |
| Complementary risk ratio | 1.07 | 1.06-1.08 | 1.02-1.13 | 65.51 |
| Risk ratio | 1.57 | 1.48-1.66 | 1.23-1.99 | 36.88 |
| Odds ratio | 1.75 | 1.63-1.88 | 1.29-2.38 | 39.06 |
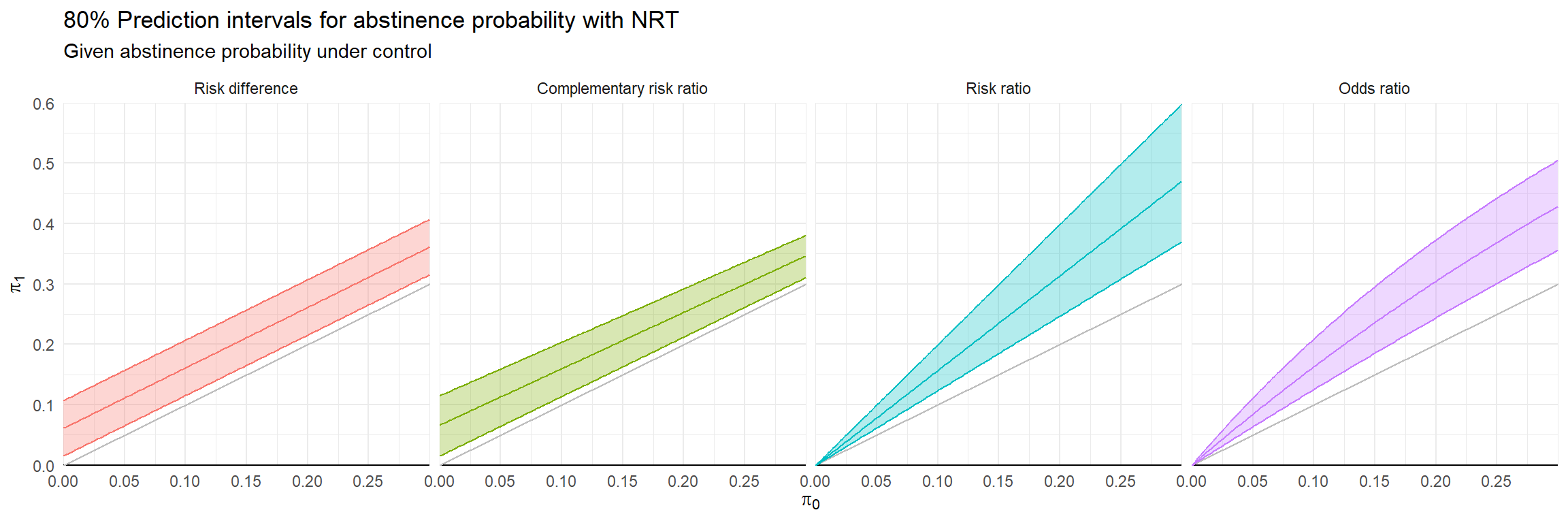
Effect metric comparison
Goal: evaluate predictions of \(\hat\pi_{0i}\), \(\hat\pi_{1i}\) using log-predictive density.
Conventional RE meta-analysis is a model for \(f(\hat\pi_{0i}, \hat\pi_{1i})\).
Possible auxiliary models for \(\hat\pi_{0i}\) or \(\hat\pi_{1i}\):
Random effects meta-analysis/meta-regression
Generalized linear mixed model
Beta-binomial regression
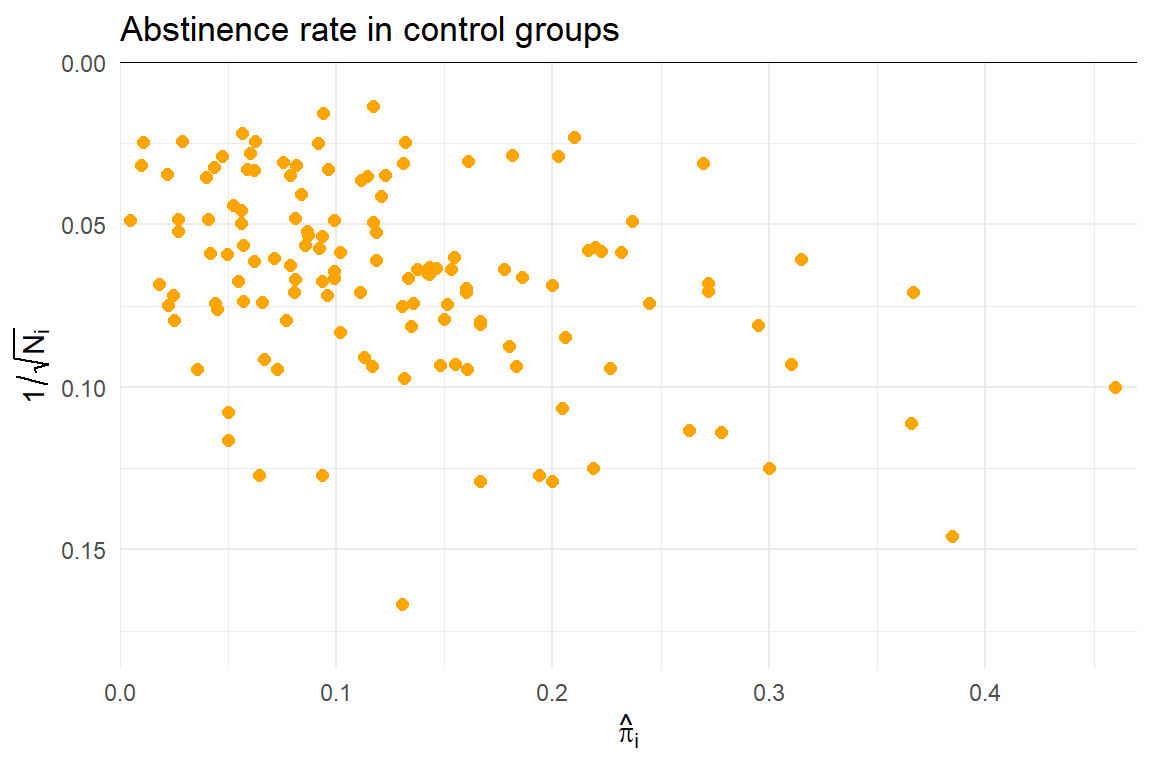
Predictive discrepancies
