Predictive Checks of Statistical Models for SCD Data
An Old and Under-Appreciated Method for Assessing Whether a Model is Any Good
2025-05-15
Brain-dump questions

Editor perspective: What common problems are you seeing in manuscript review with respect to statistical analysis and reporting? Have you noticed any improvements in application of statistical analysis?
Researcher perspective: What challenges or limitations are you running into in applying statistical analysis that you think could potentially enhance your work?
Student perspective: Have you seen any applications of statistical analysis that you found especially compelling? Have you learned about any statistical methodology work that you find exciting or compelling?
Predictive Checks of Statistical Models for SCD Data
An Old and Under-Appreciated Method for Assessing Whether a Model is Any Good

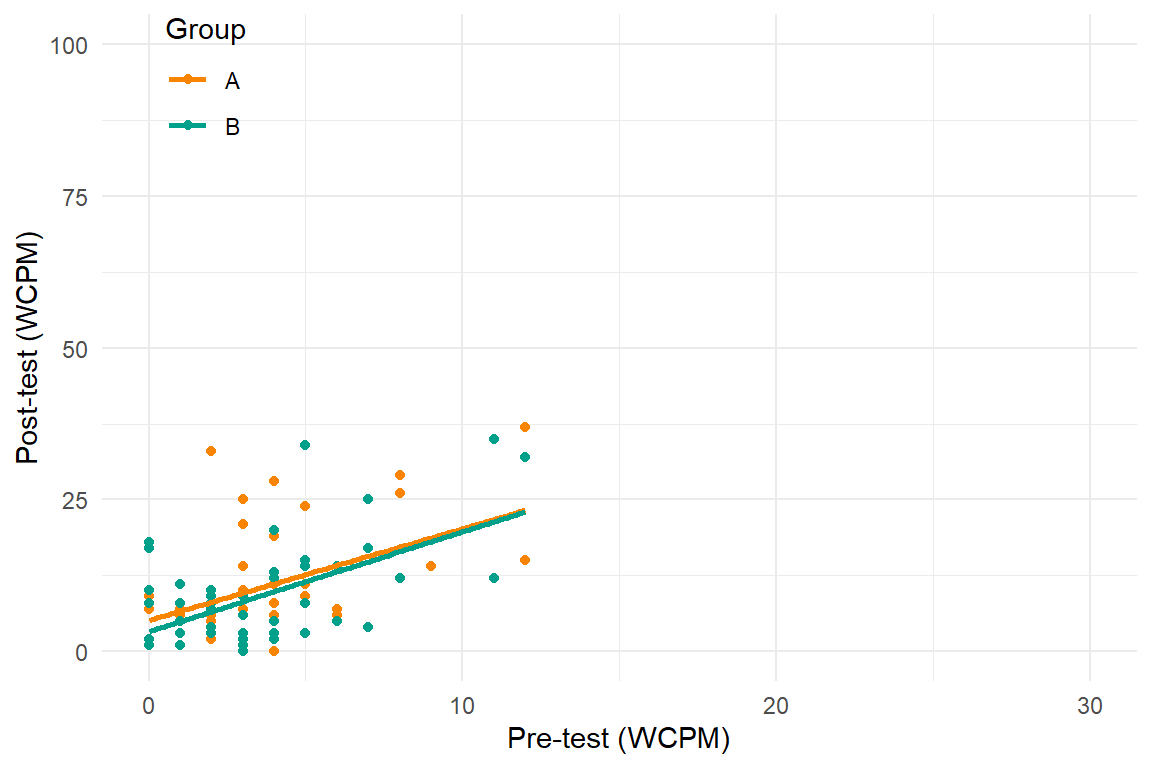
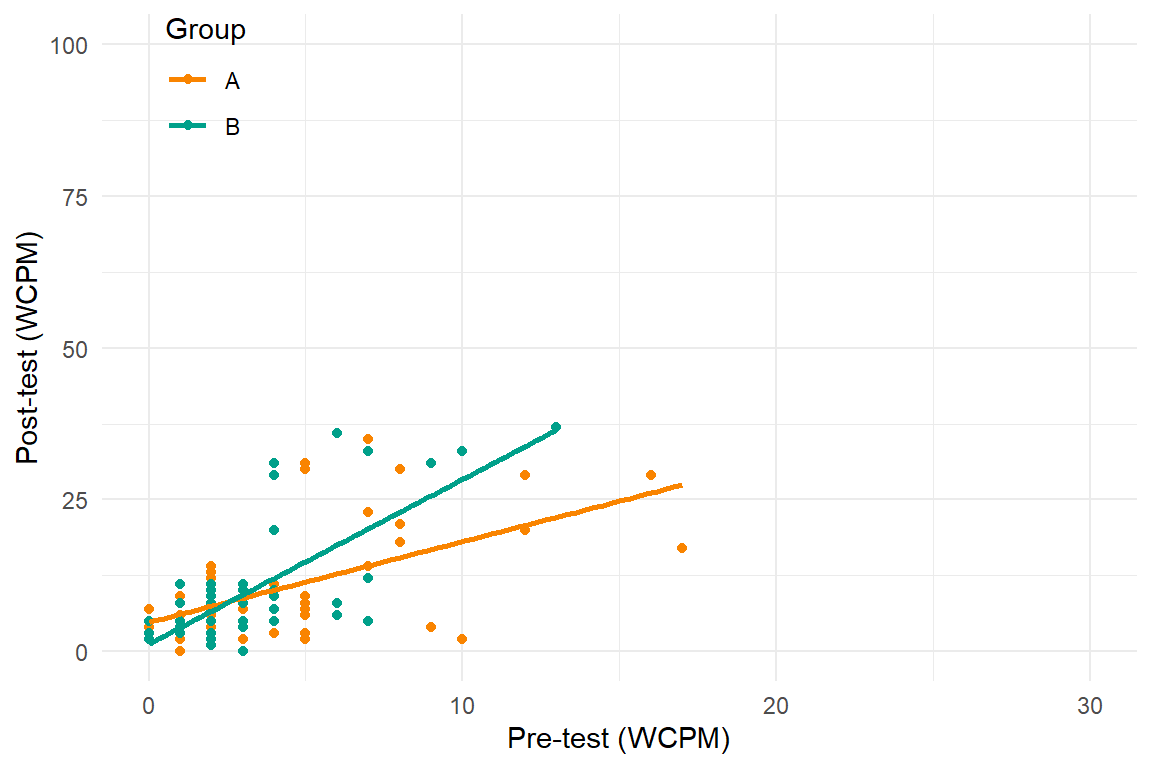
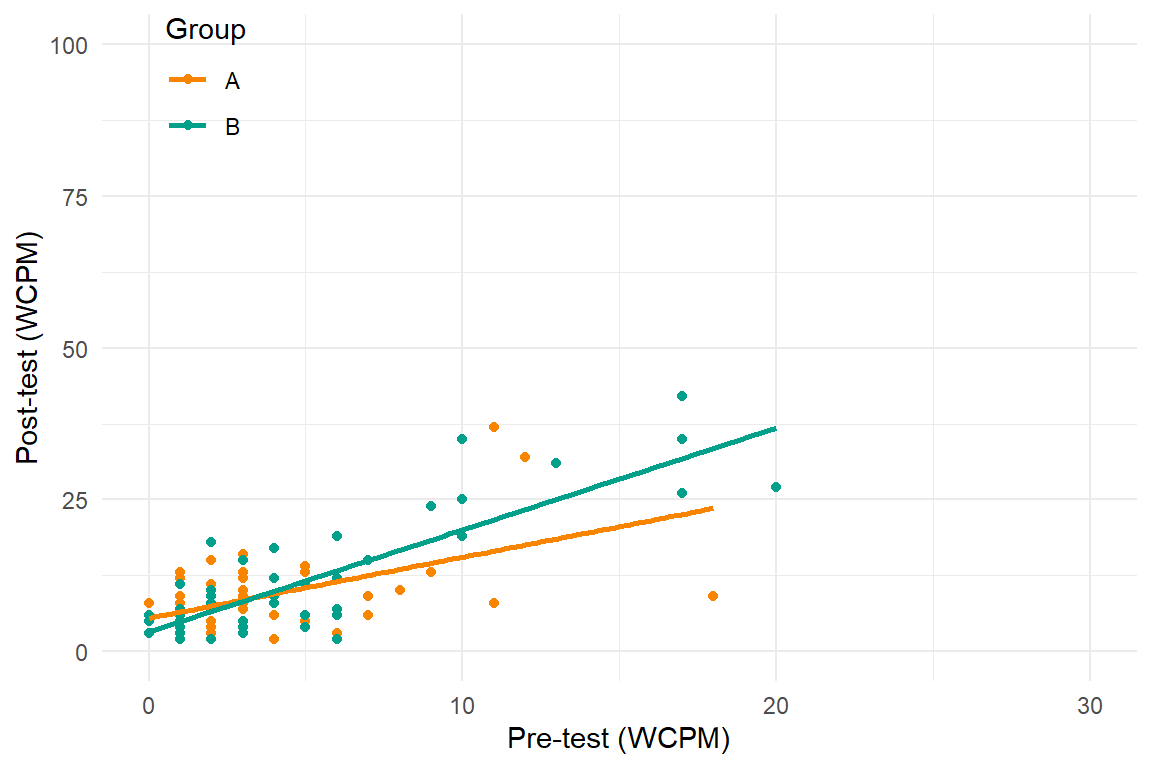
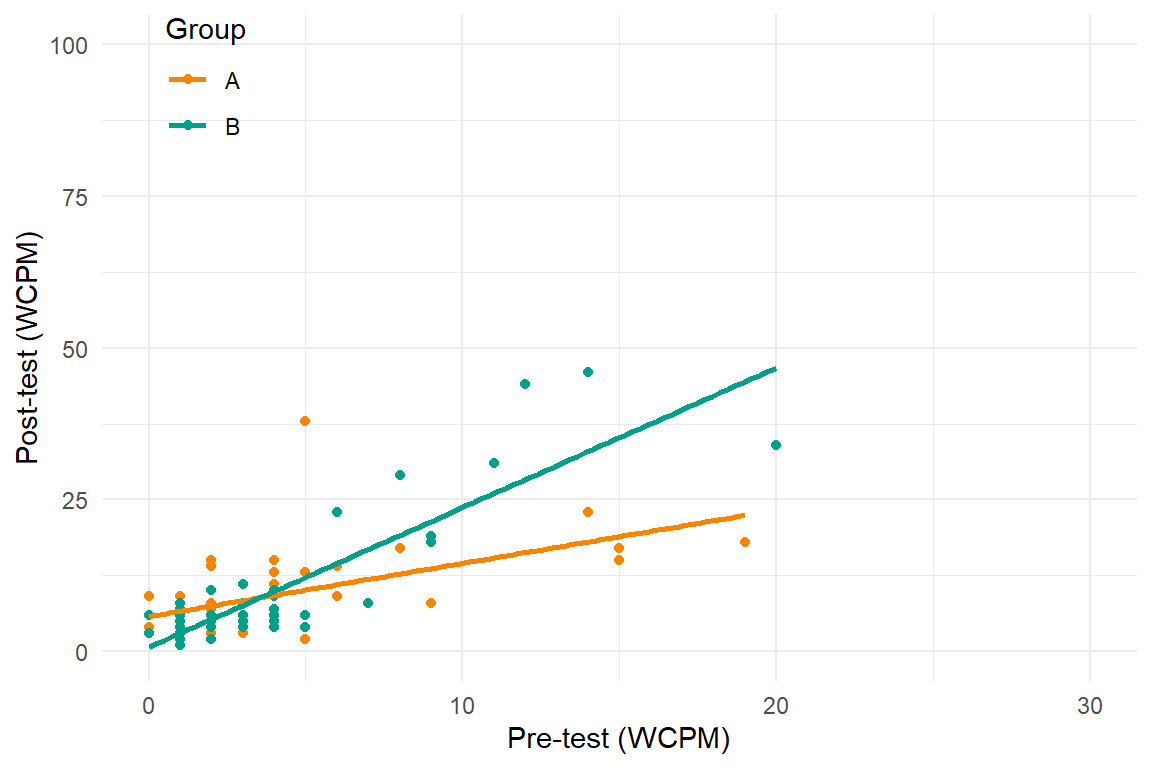
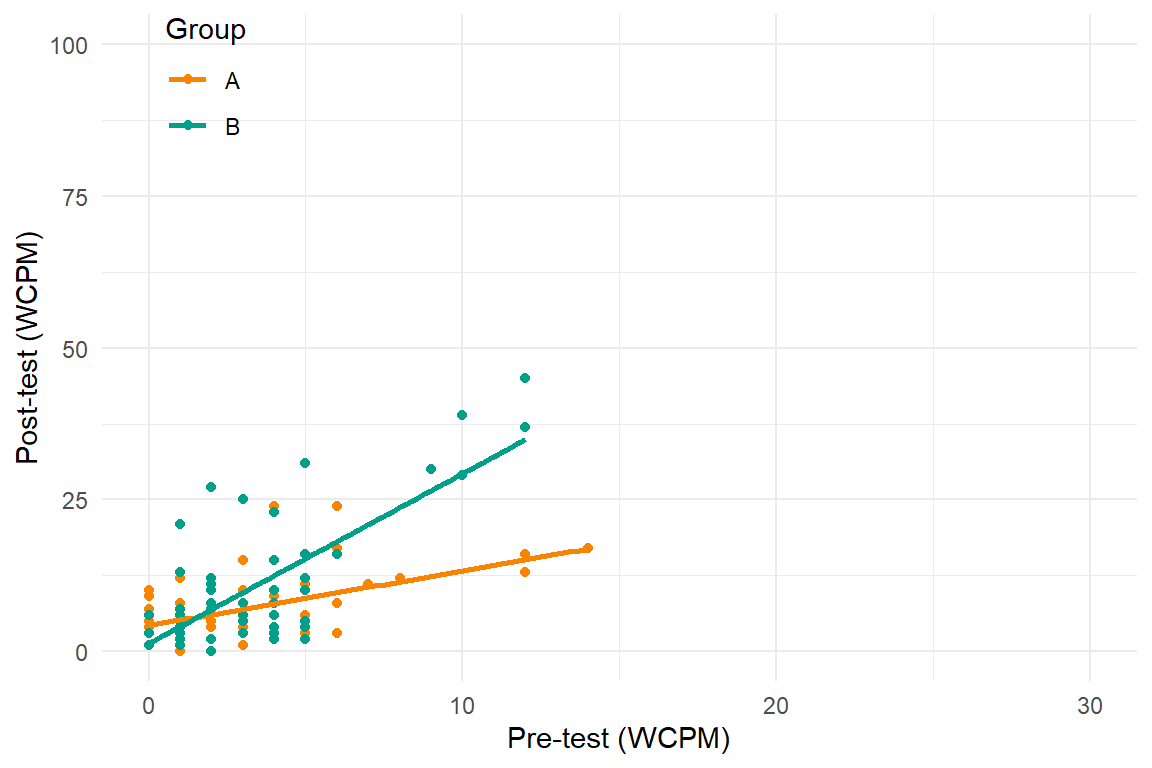
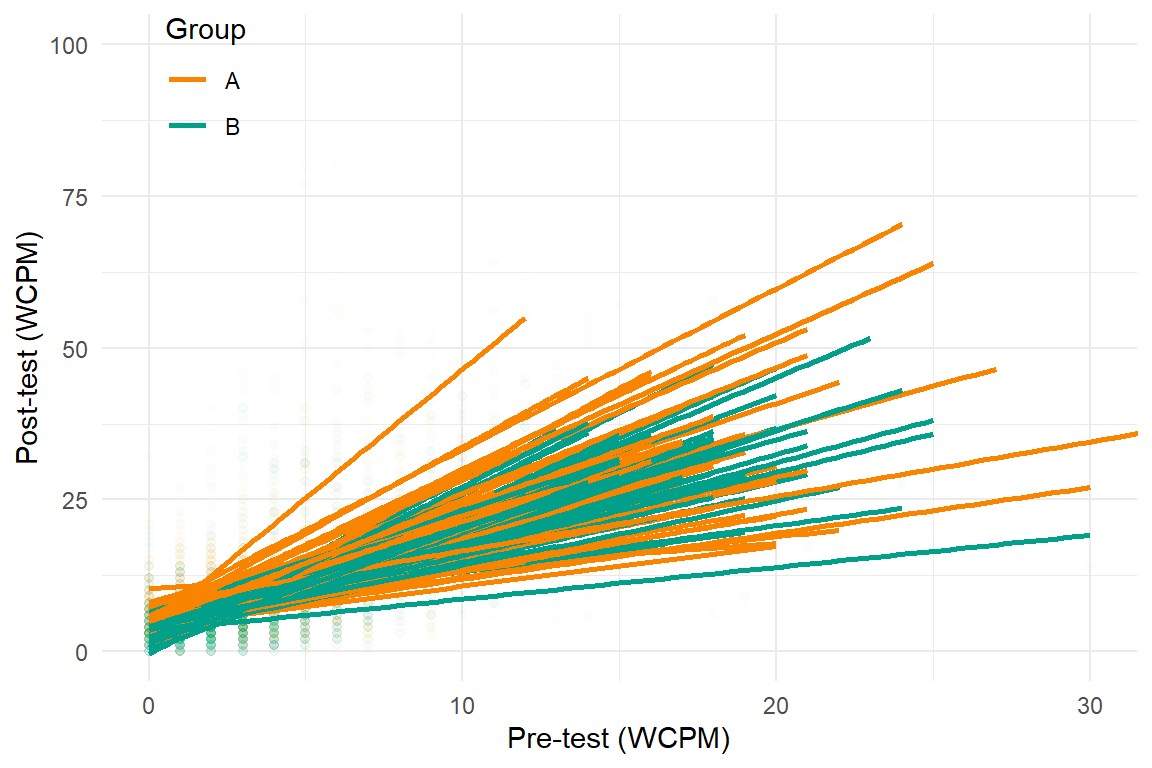
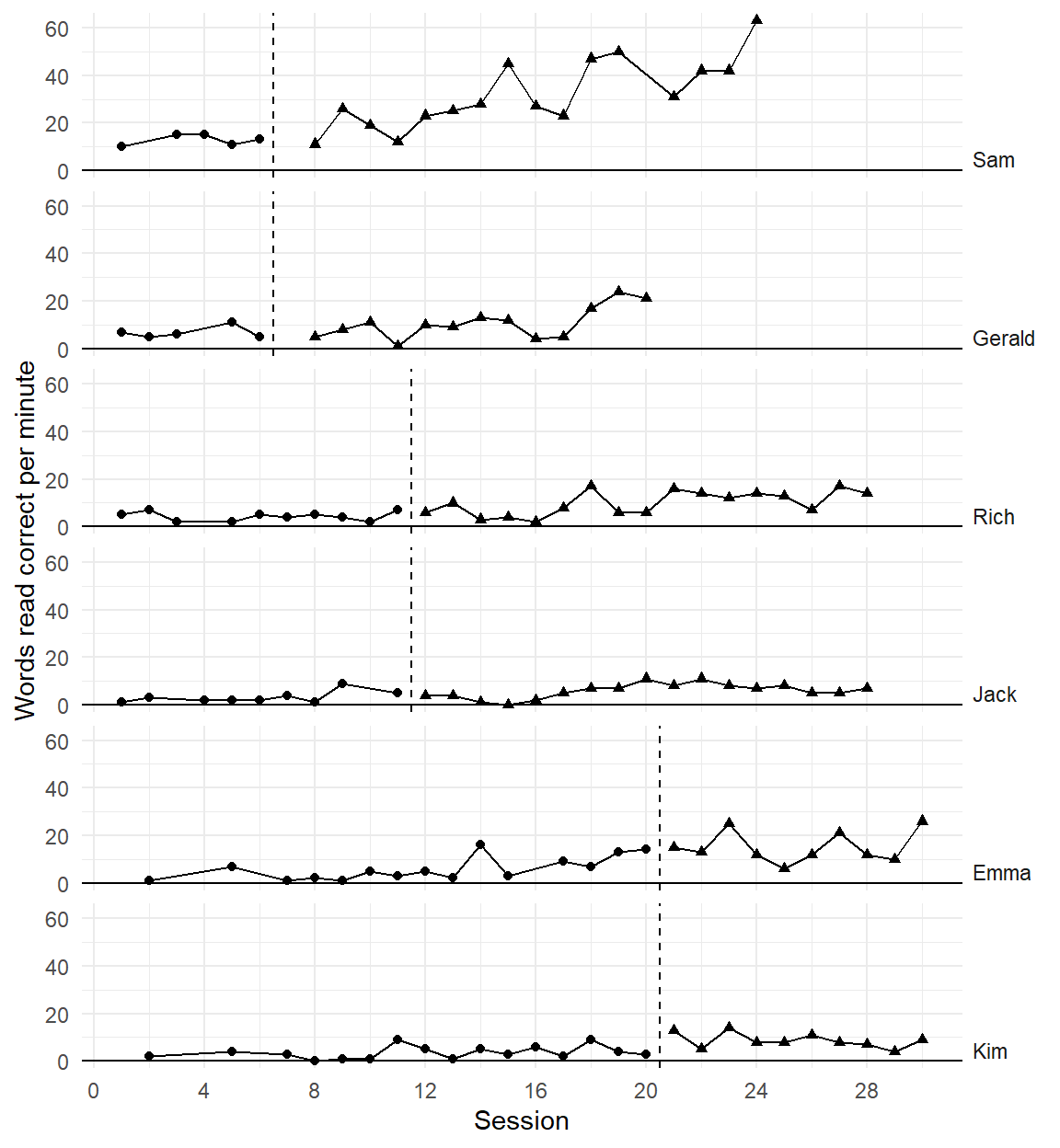
Recent developments in models for SCD data are getting more complex and technical






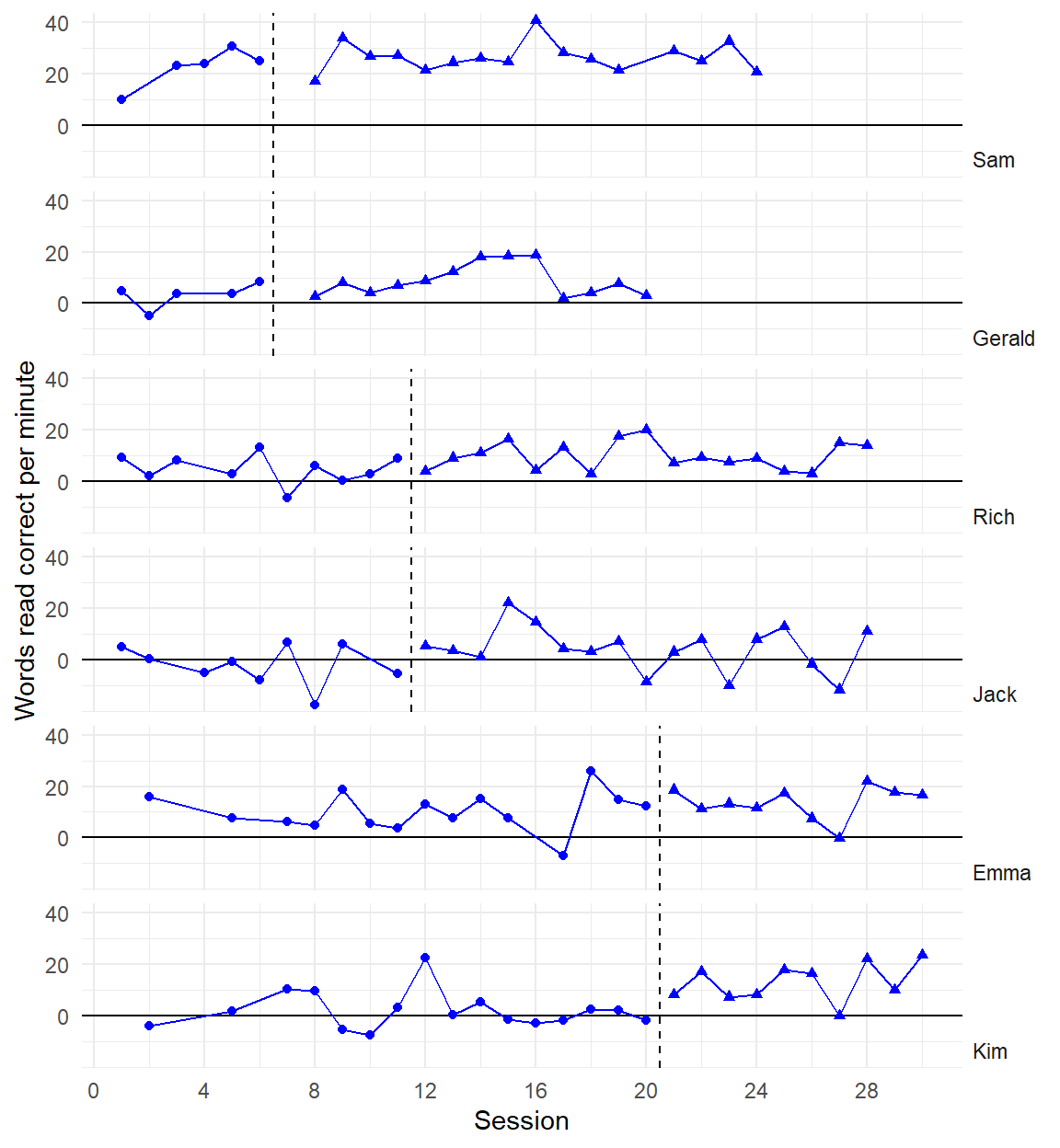
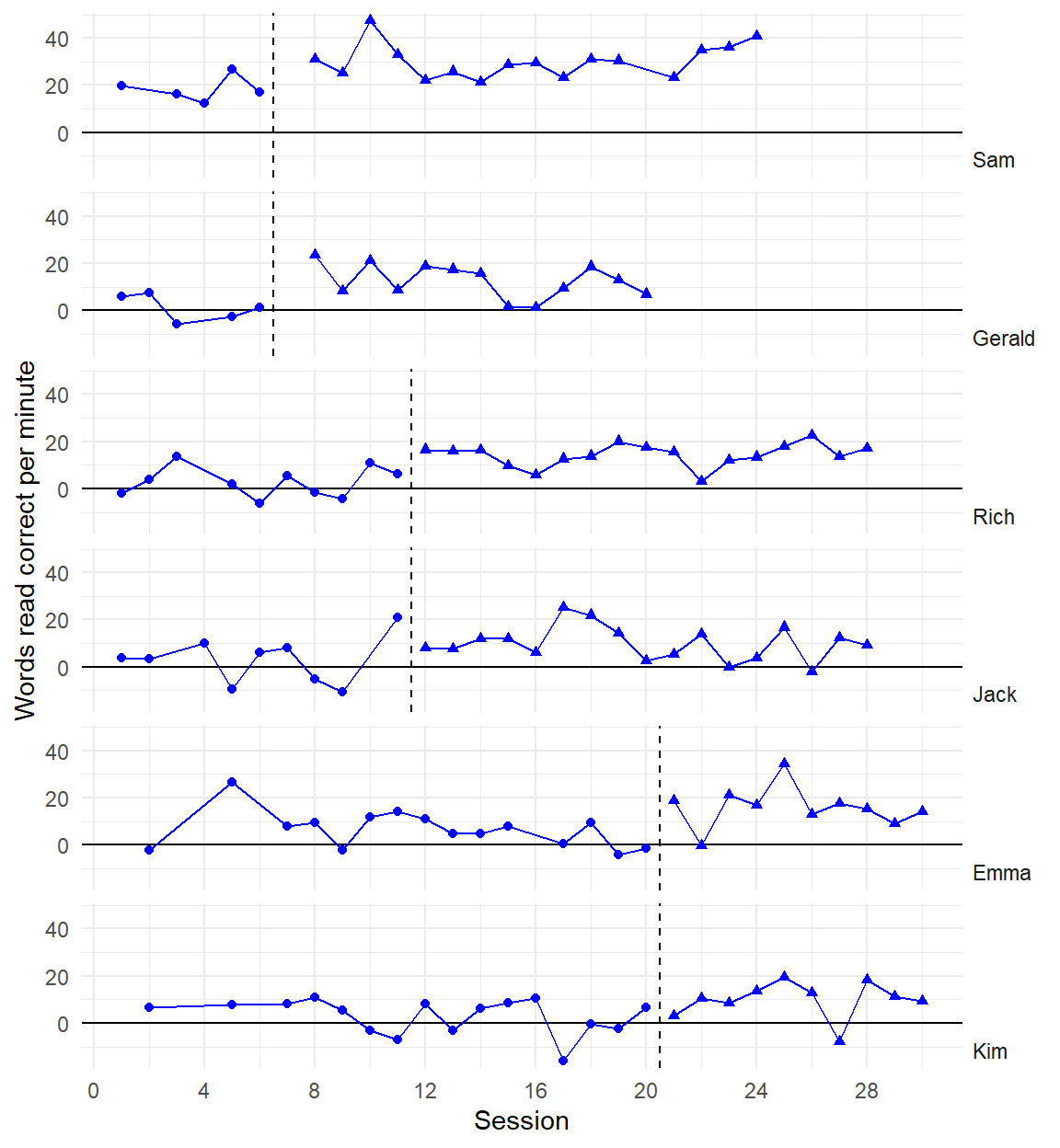
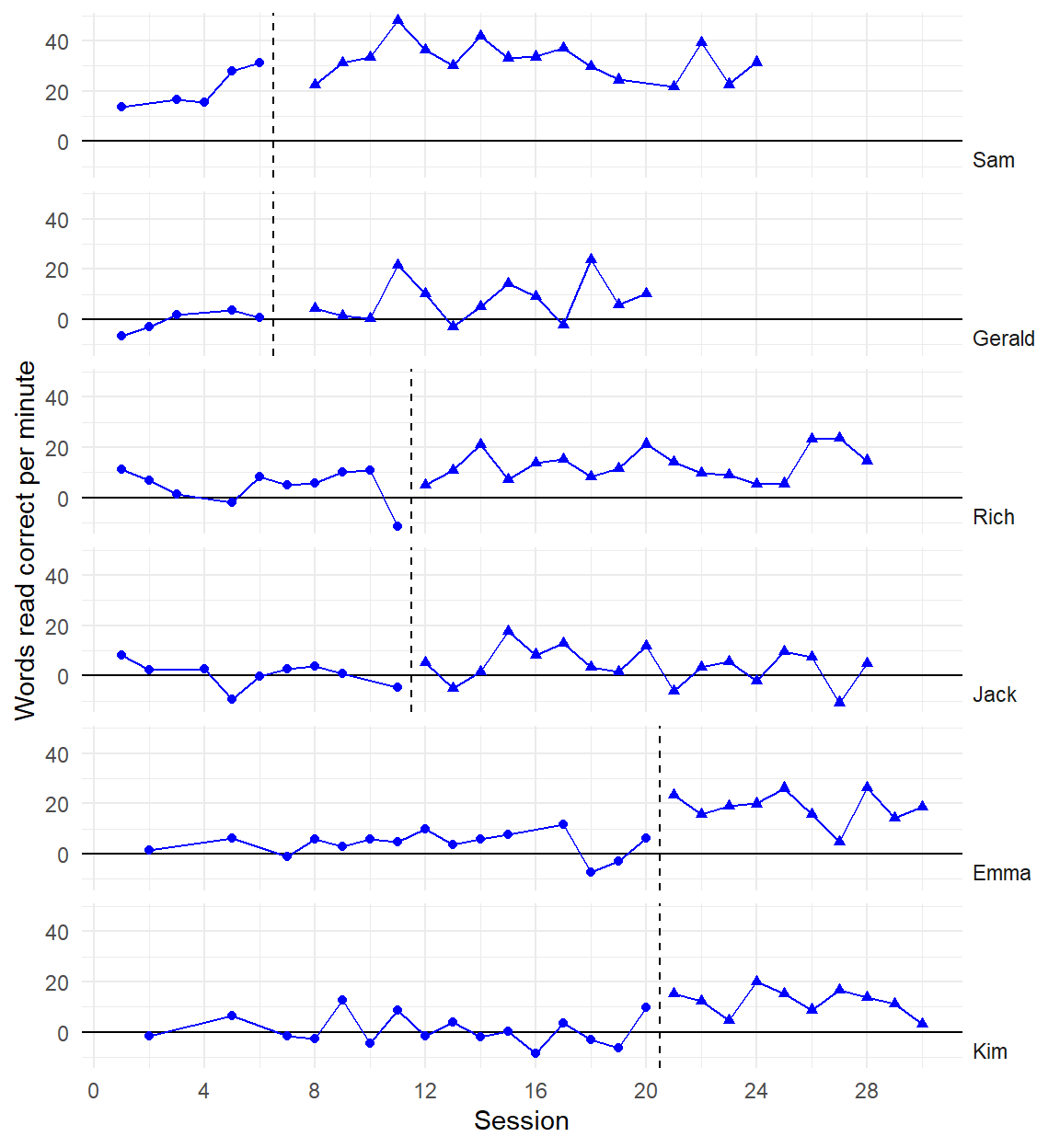
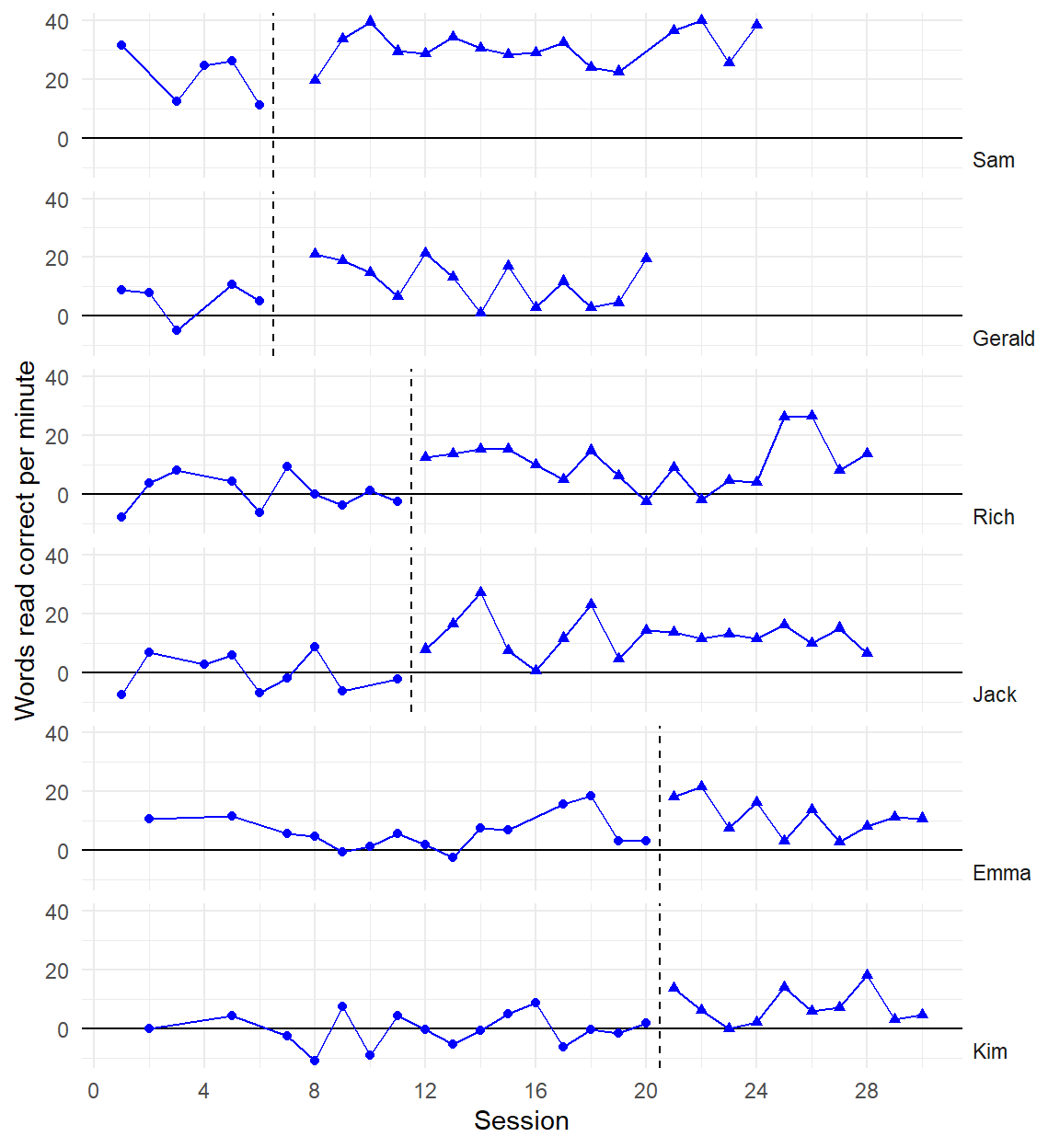
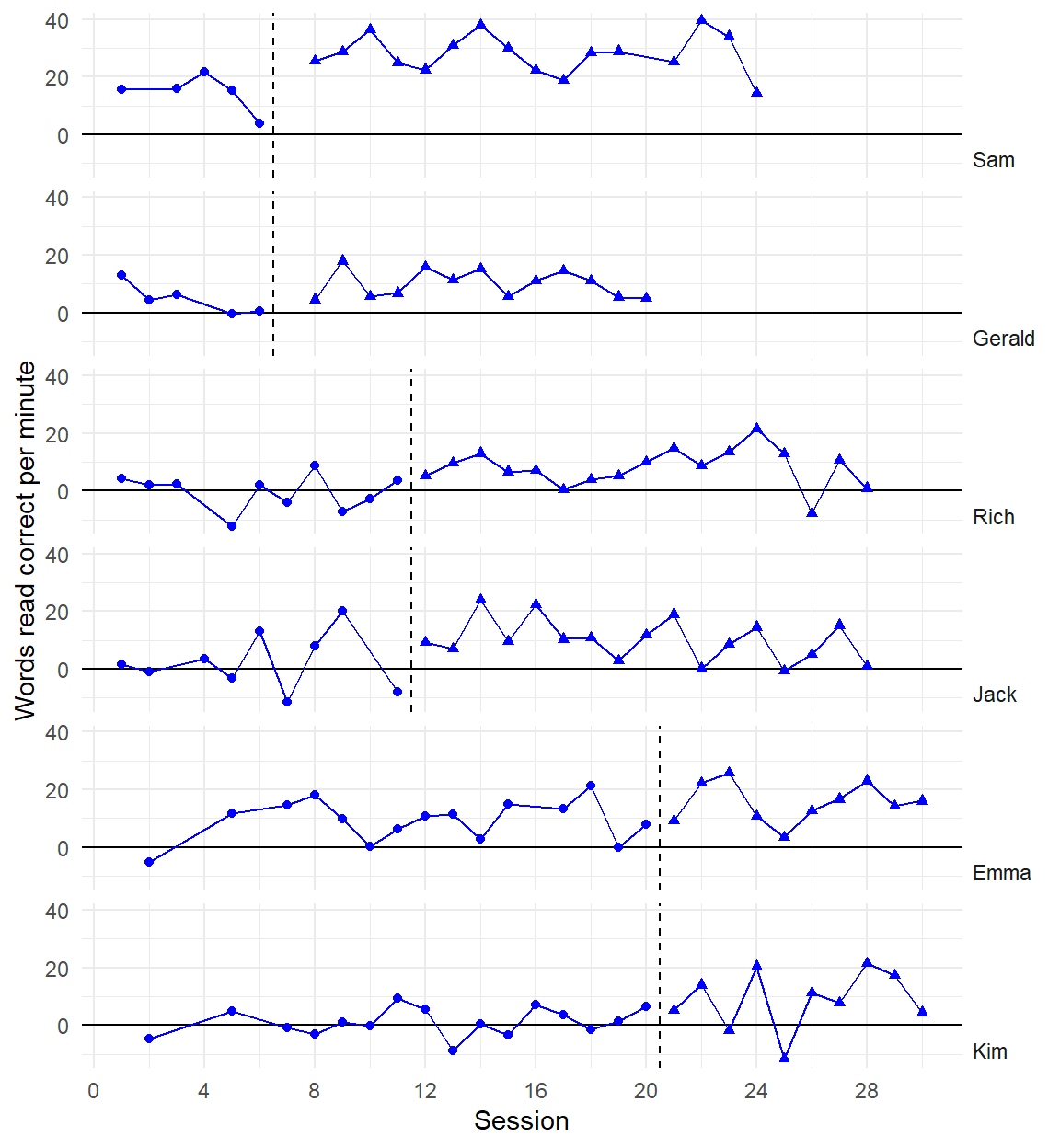
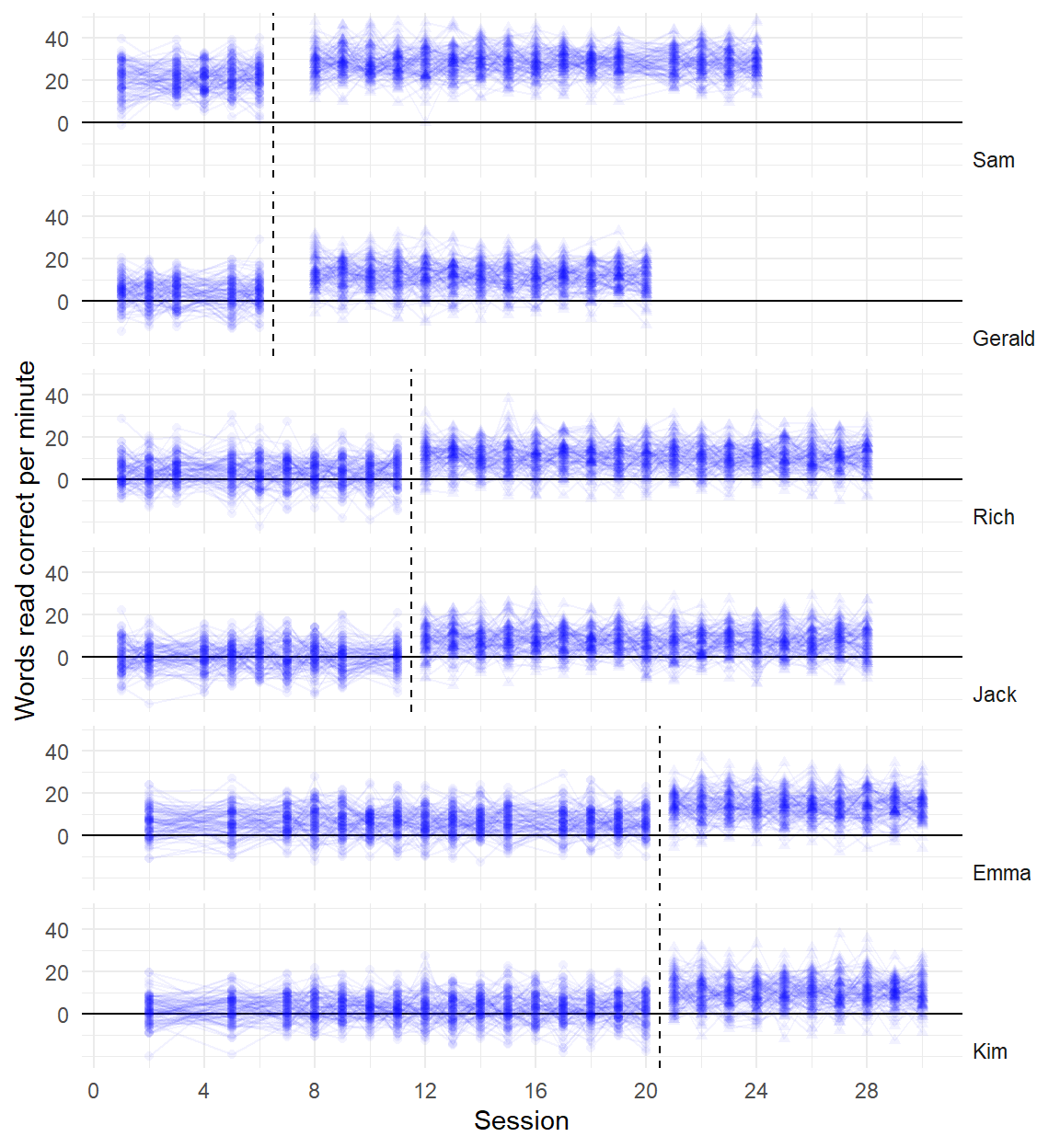
Three points of comparison
Are the simulated data points plausible considering what you know about the participants, behavior, and study context?
Are the simulated data points similar to the real data?
Are the simulated data points more realistic than data simulated from alternative models?
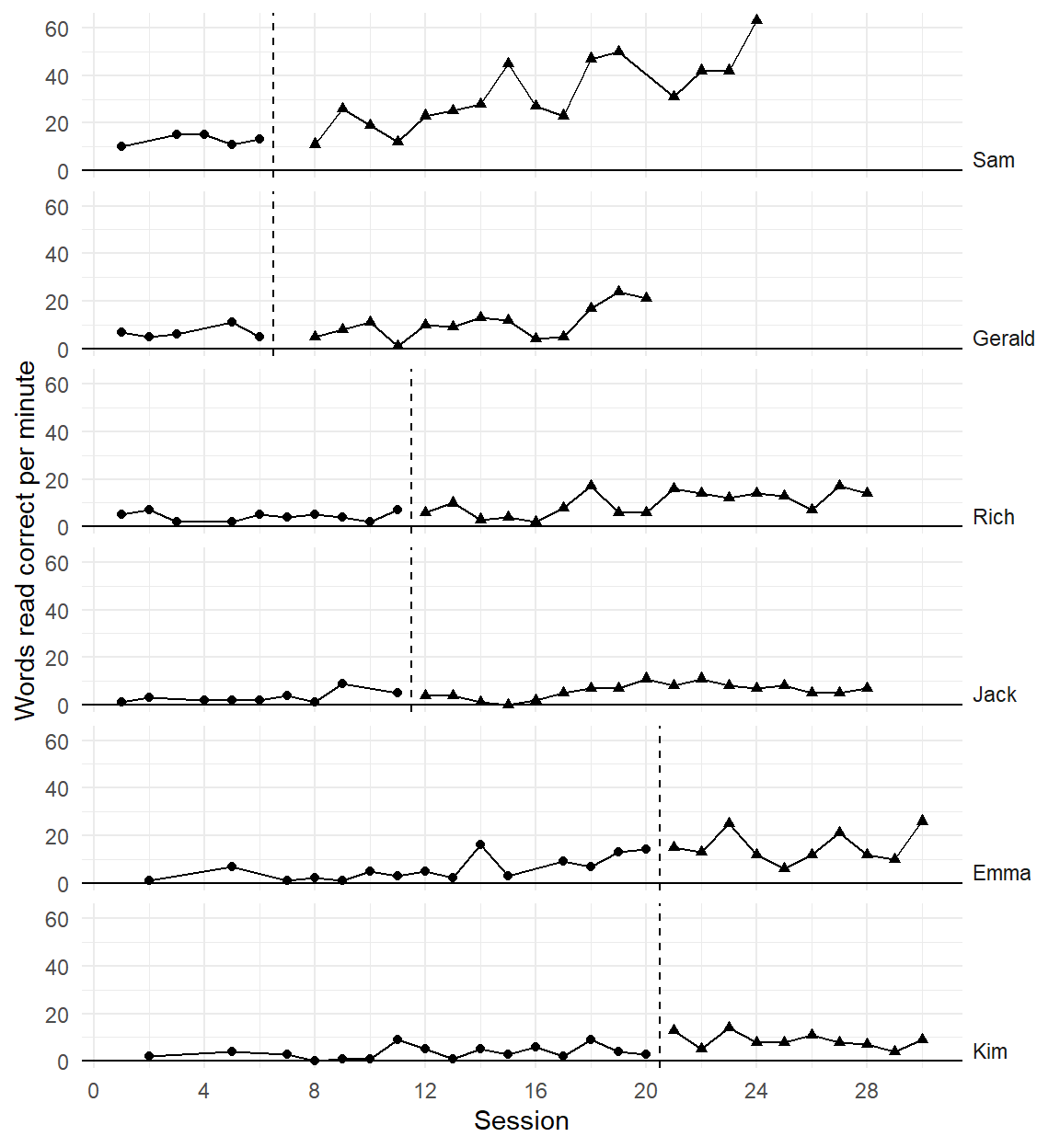
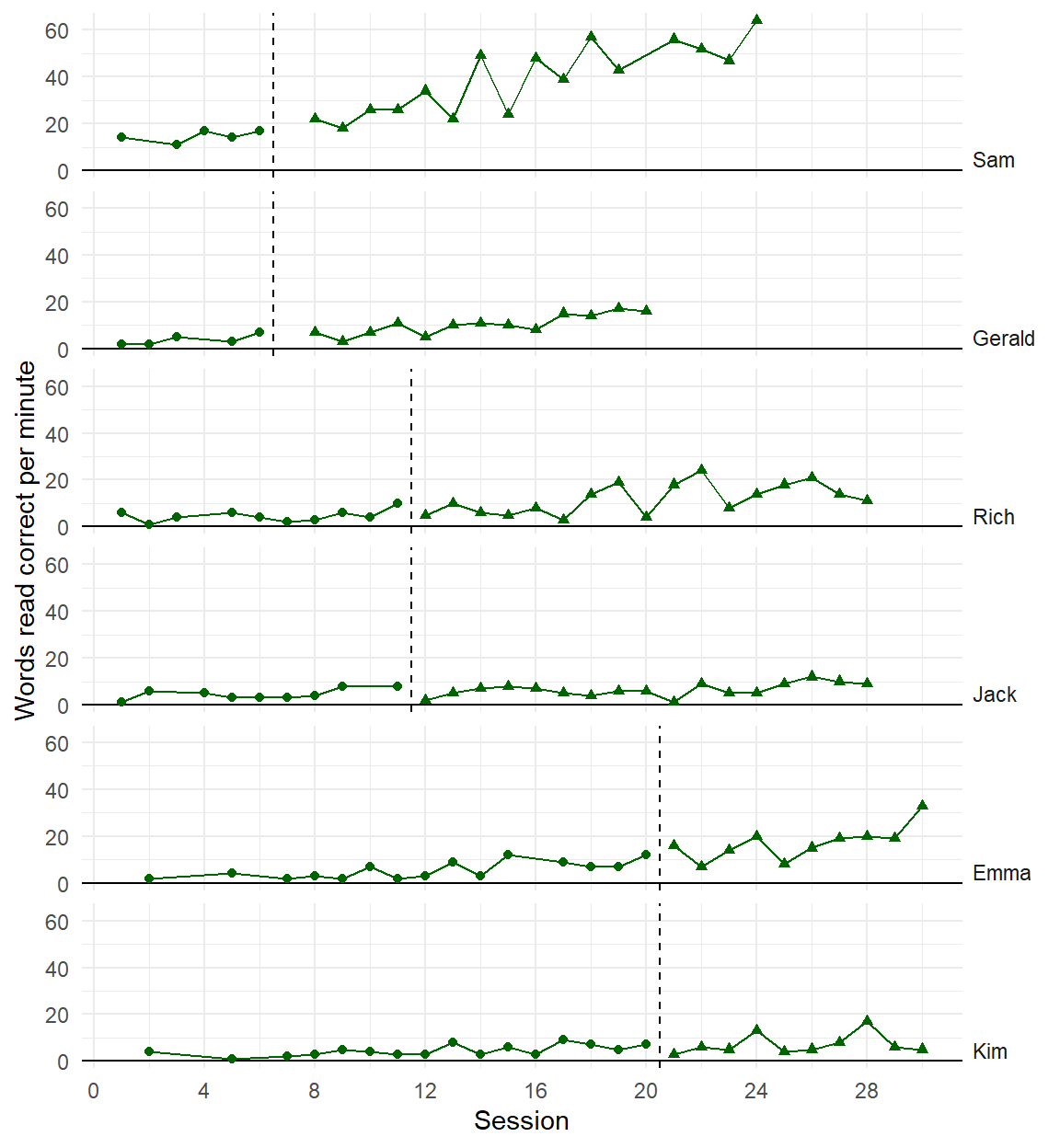
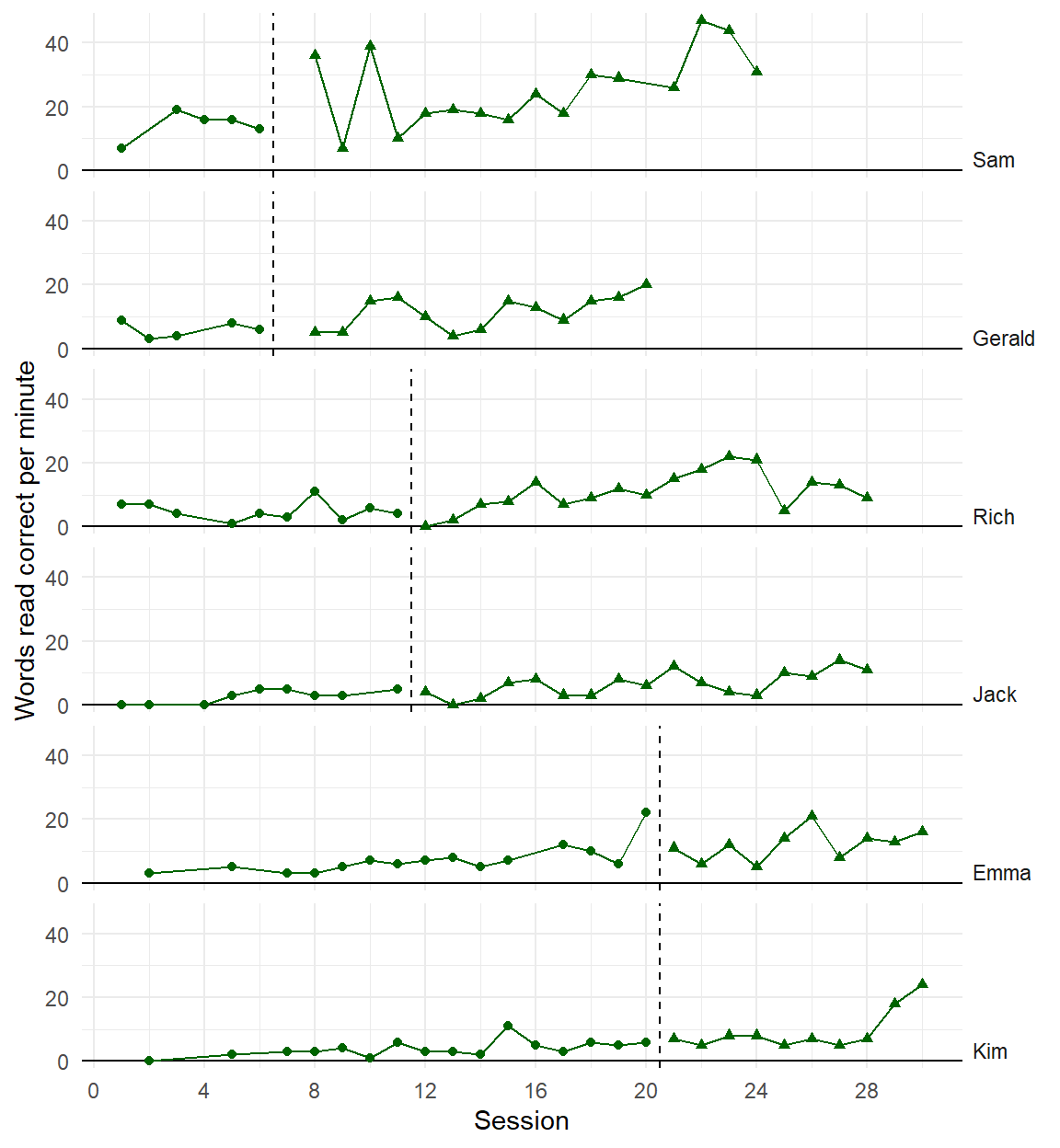
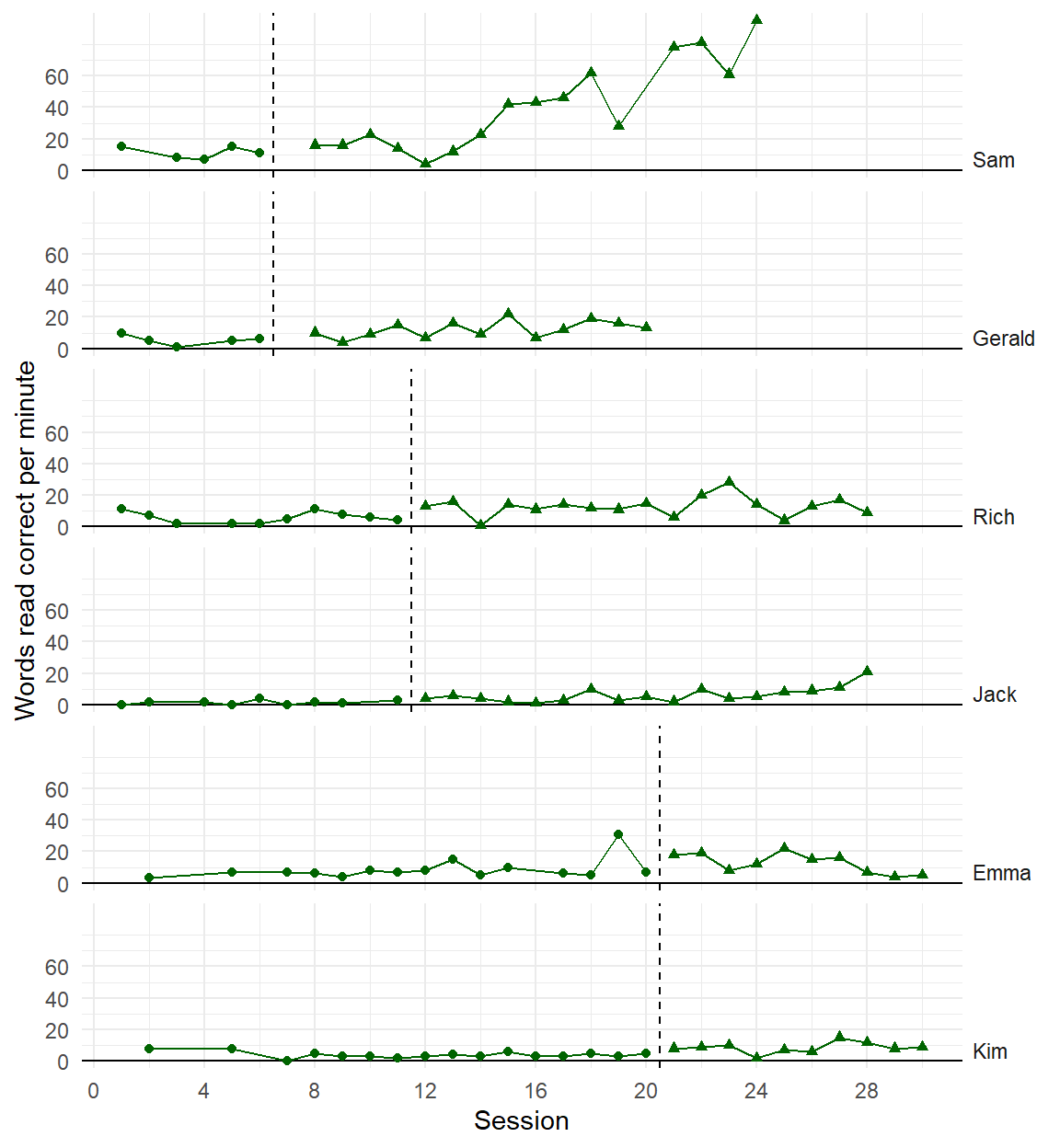
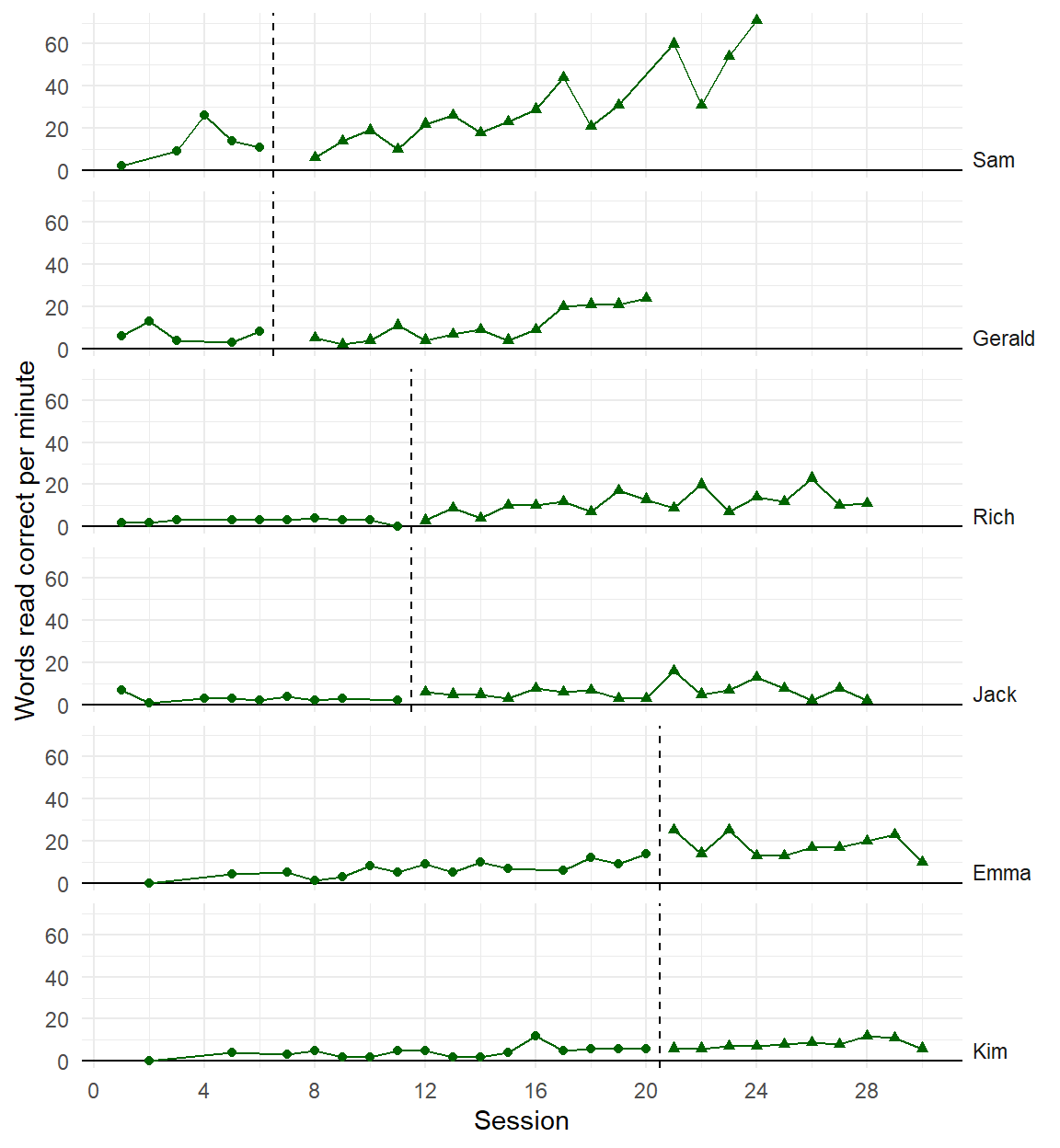
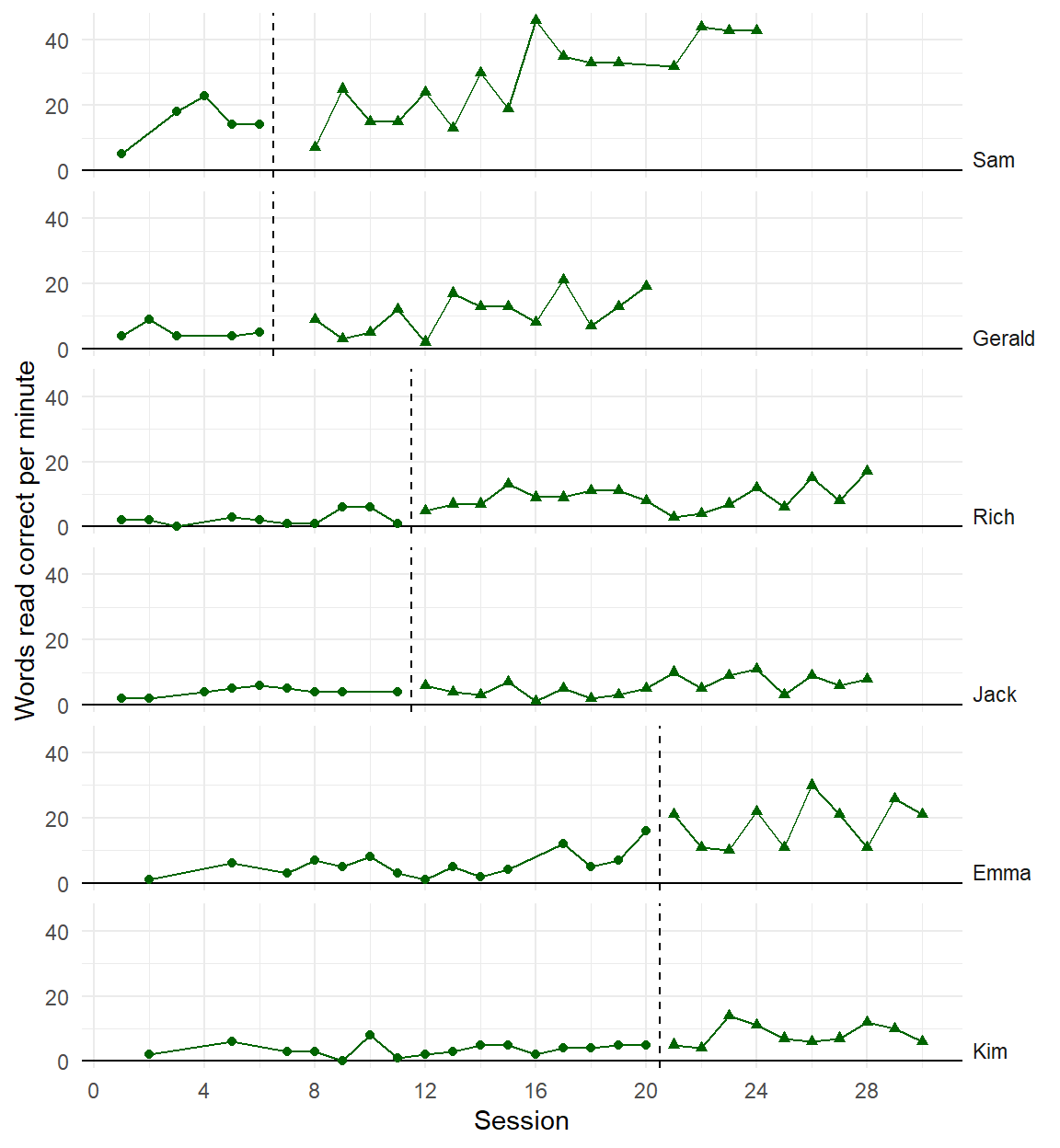
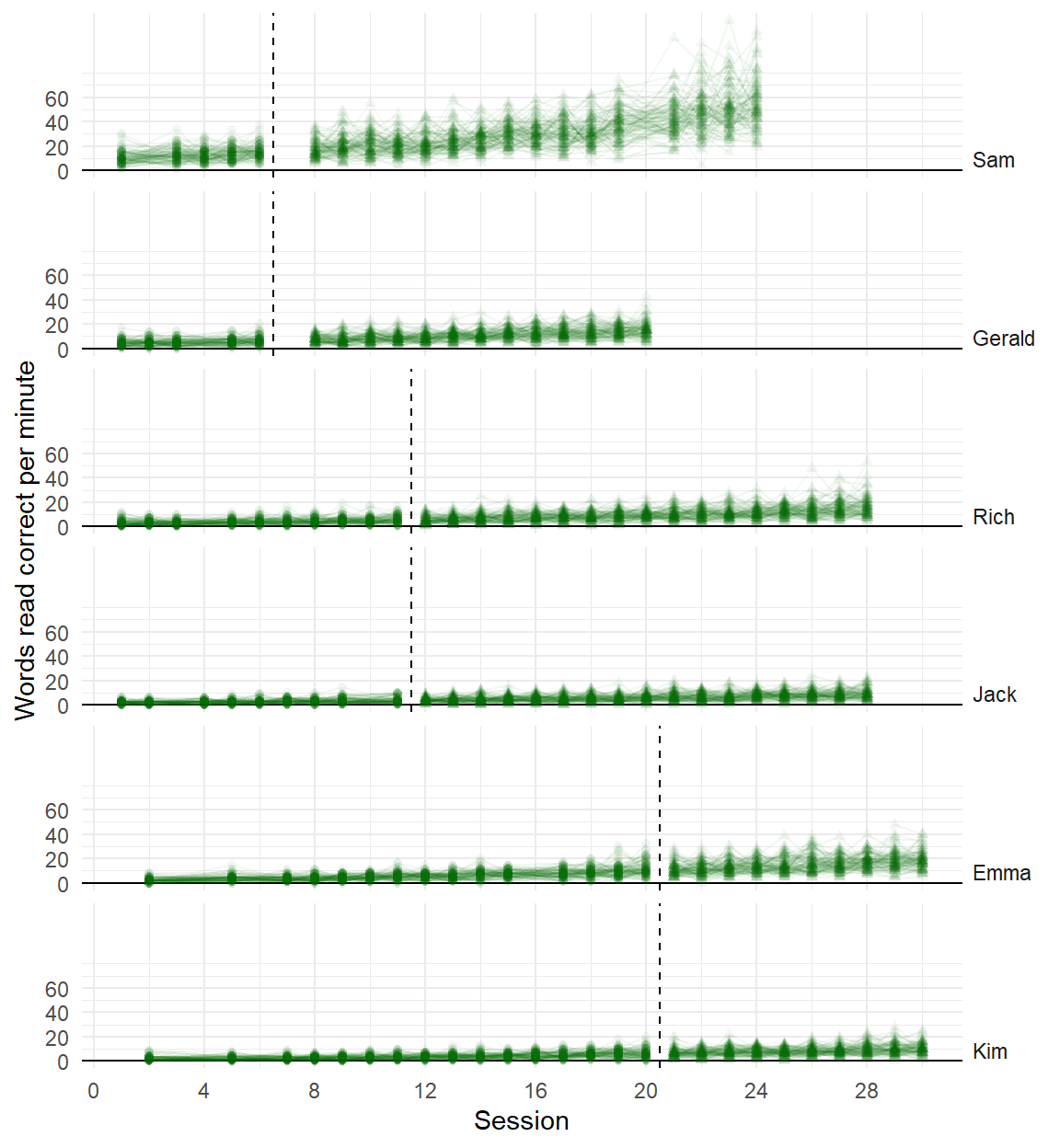
Initial observation
Poor model
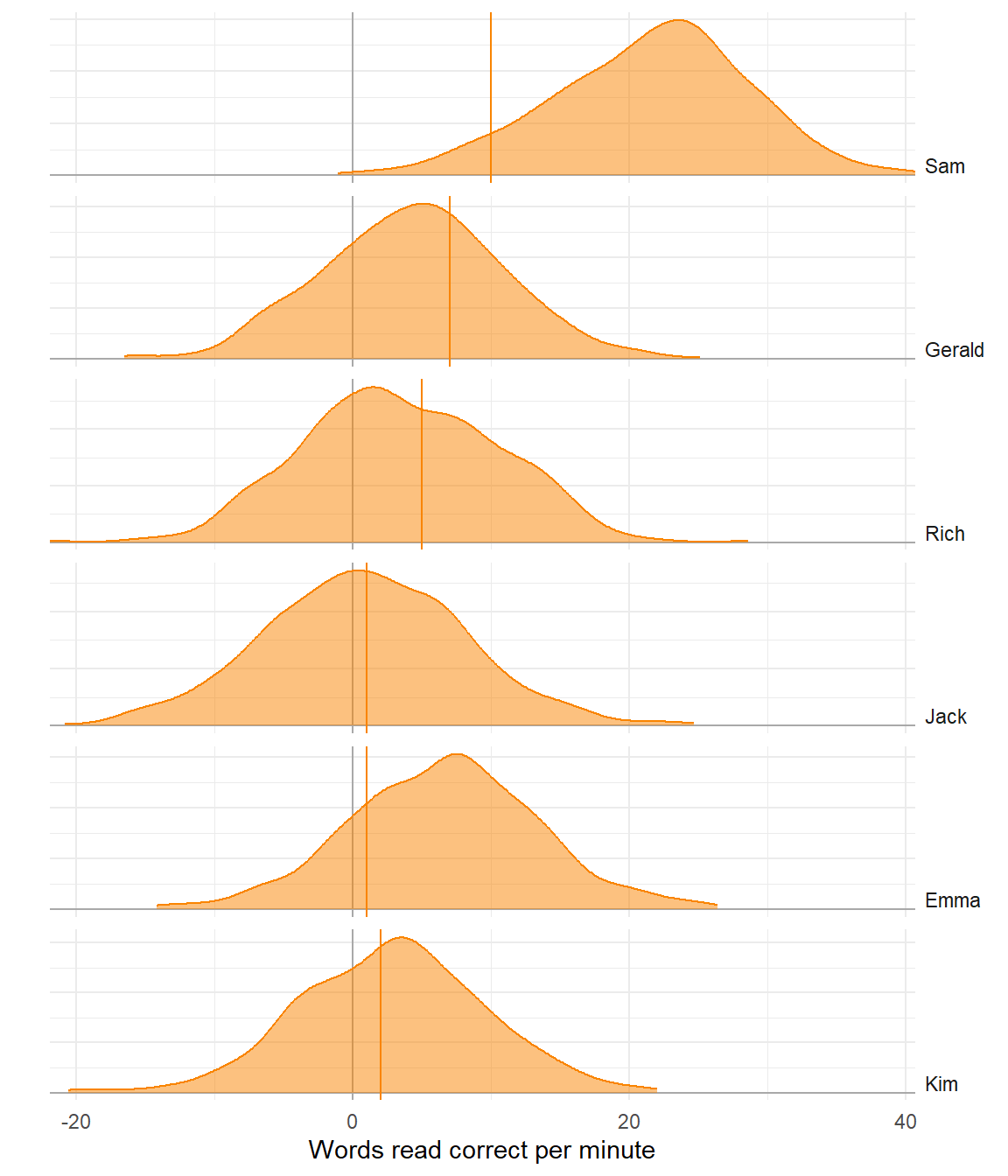
Better model
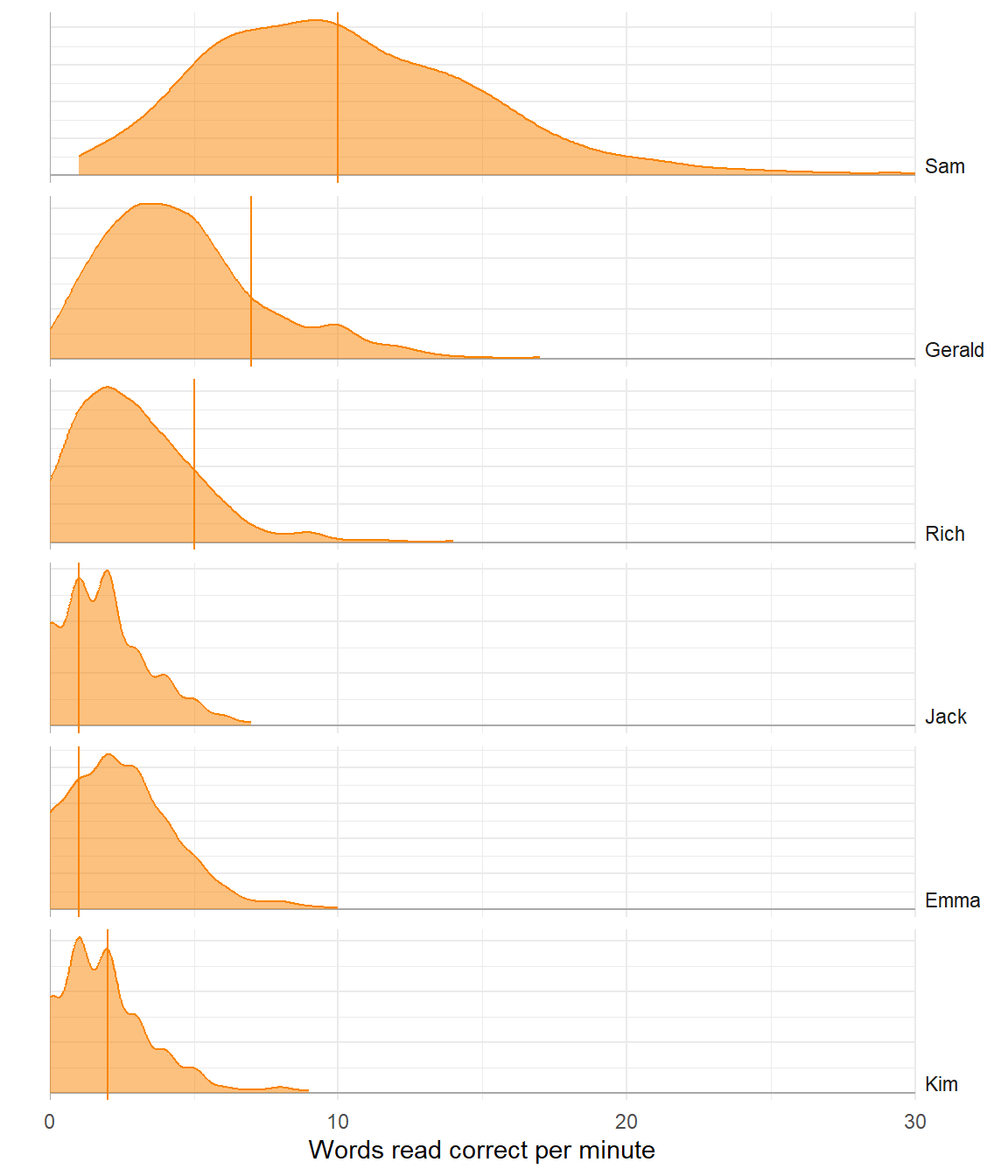
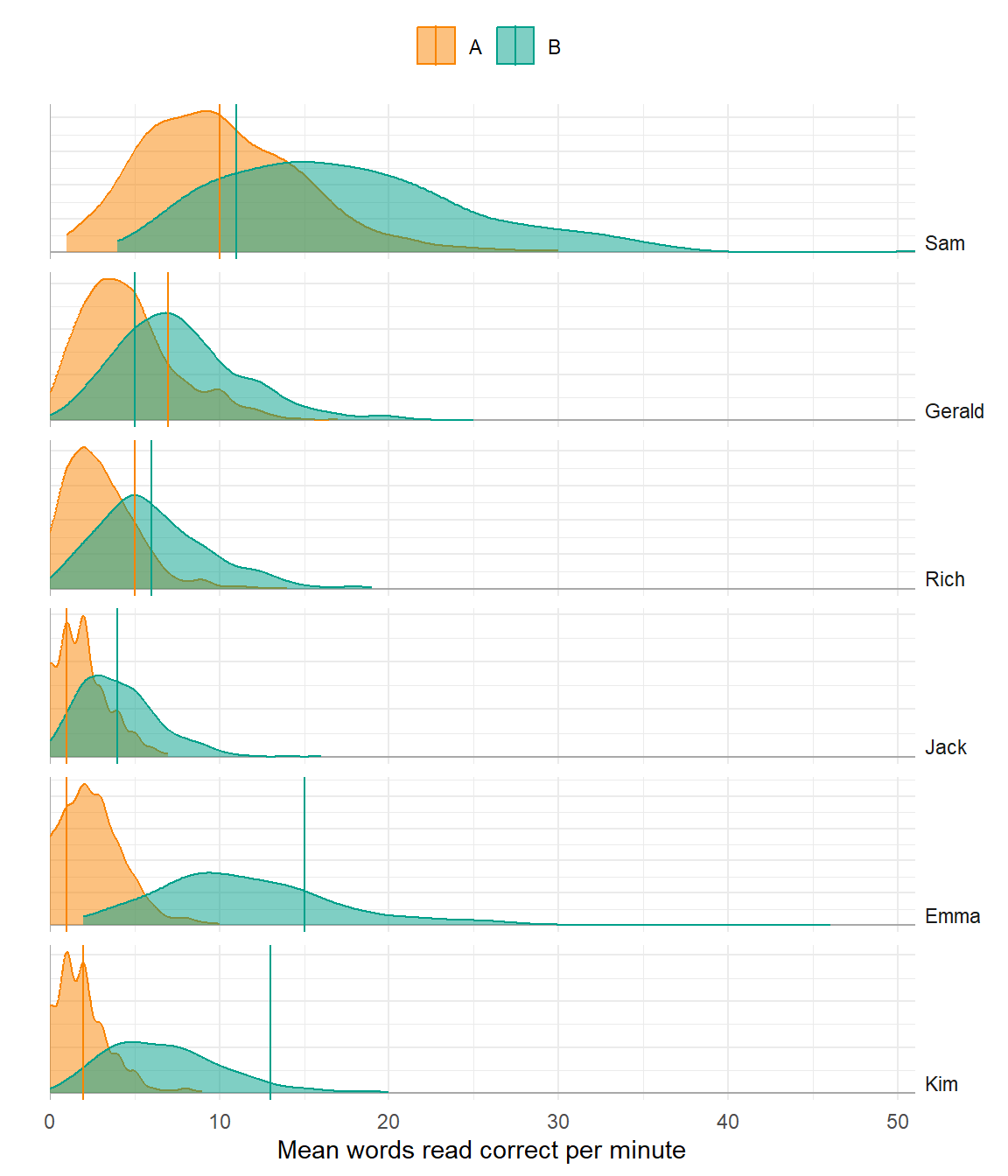
Level
Poor model
Better model
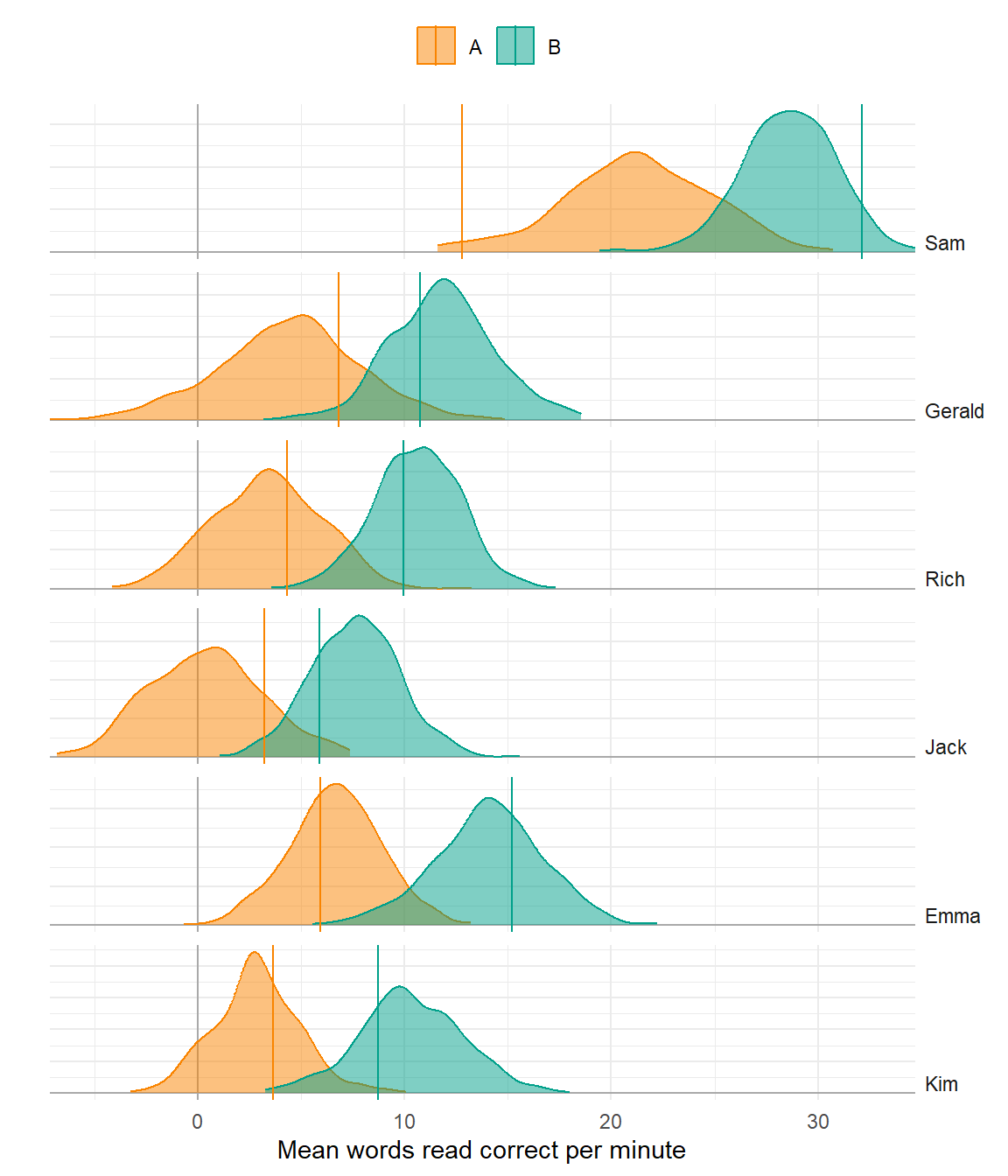
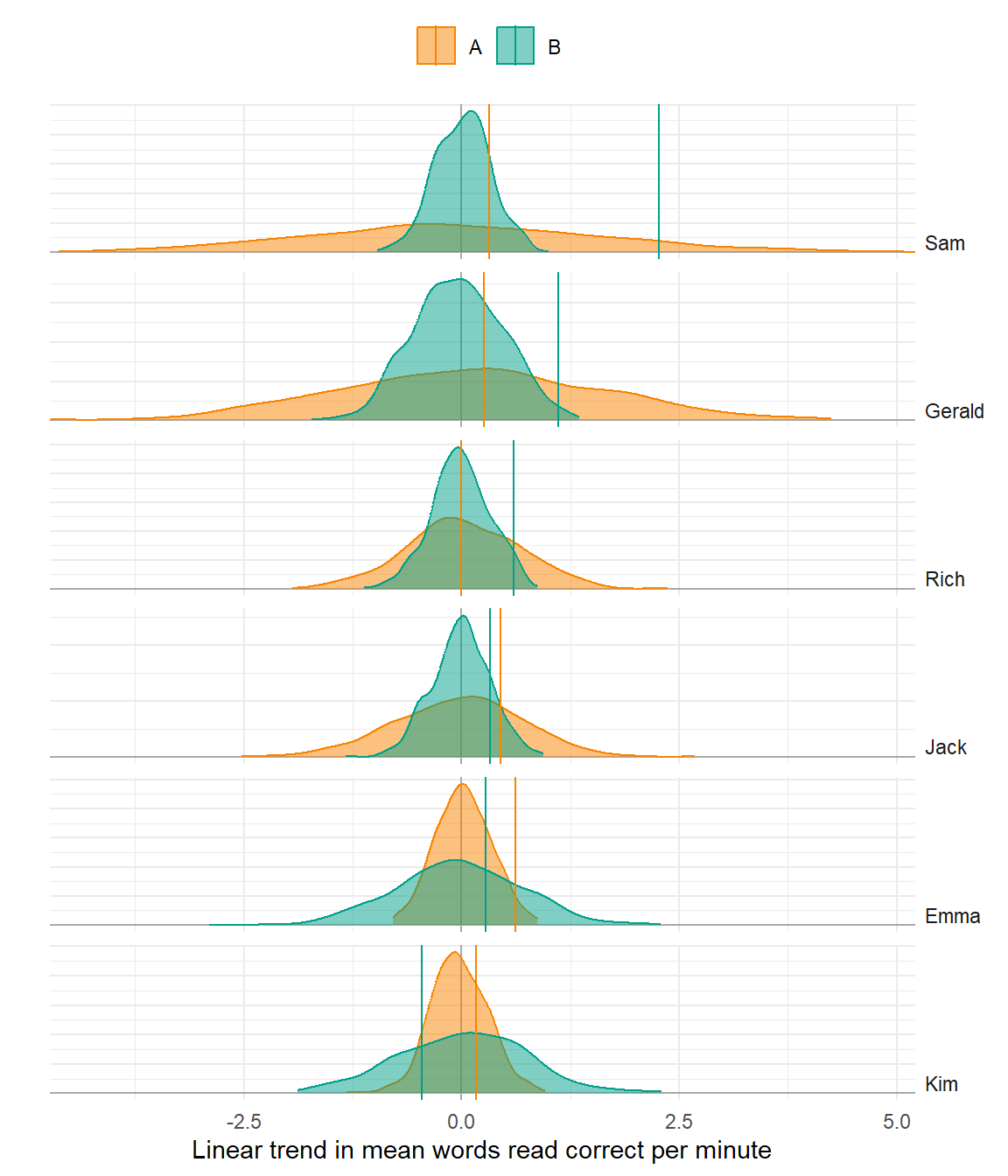
Trend
Poor model
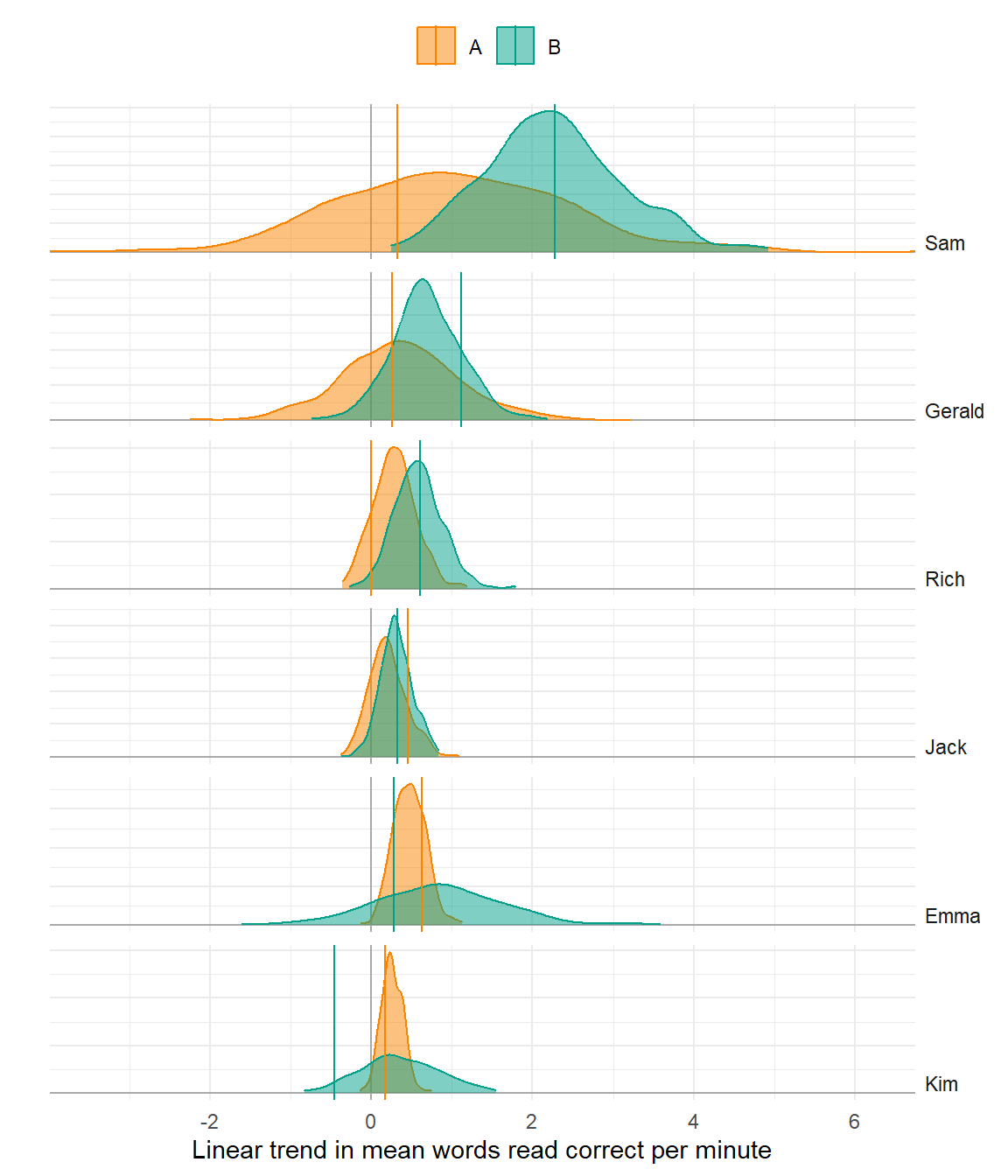
Better model
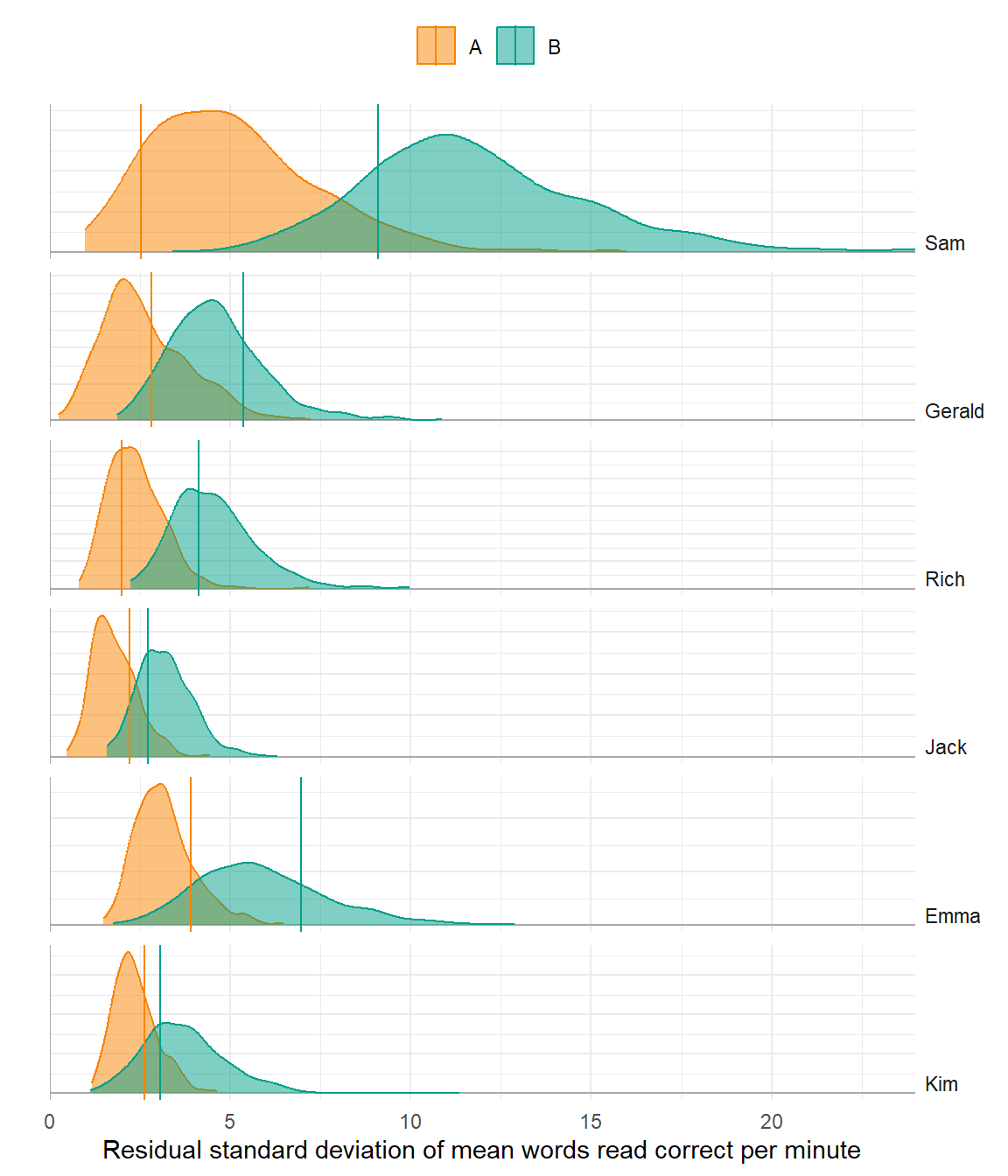
Variability
Poor model
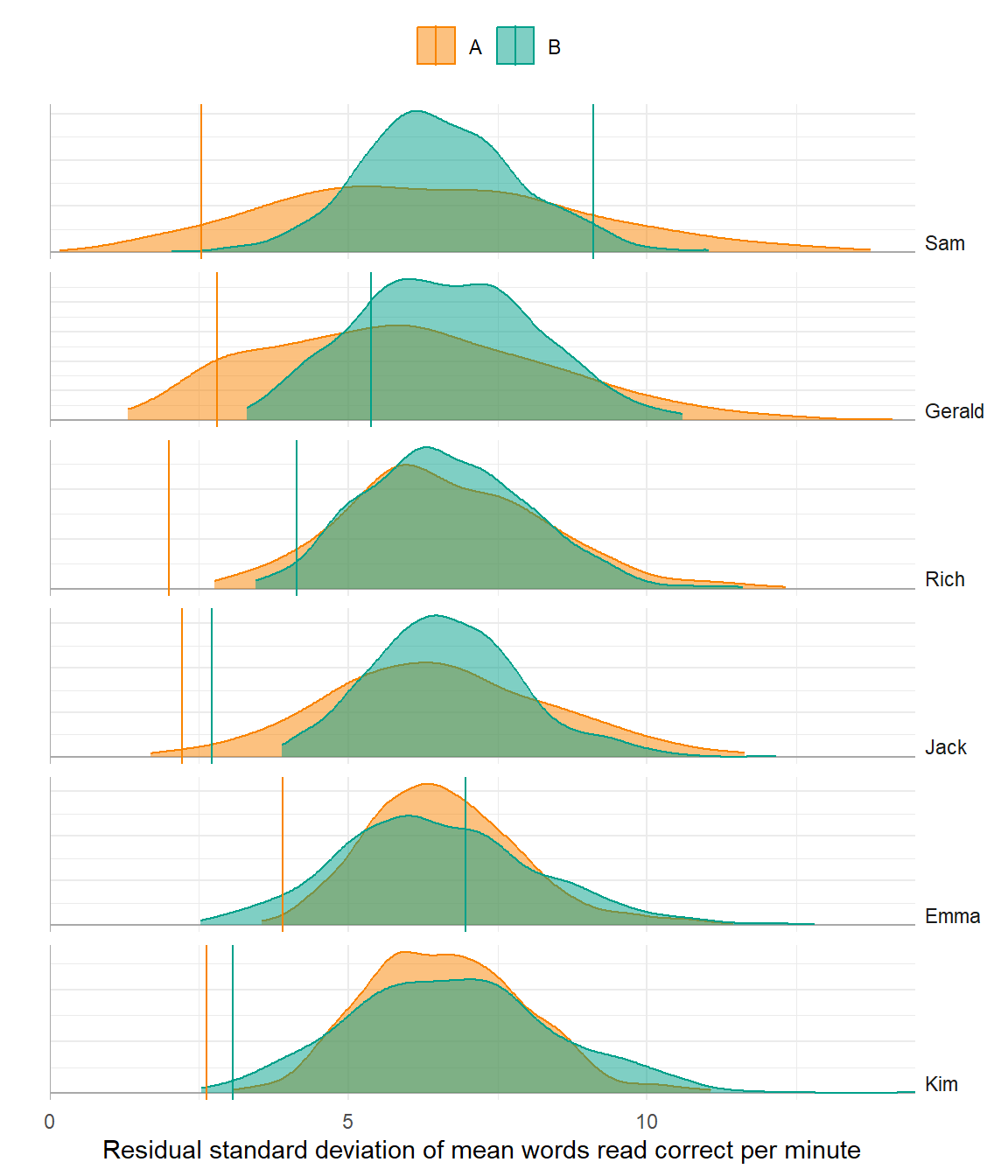
Better model
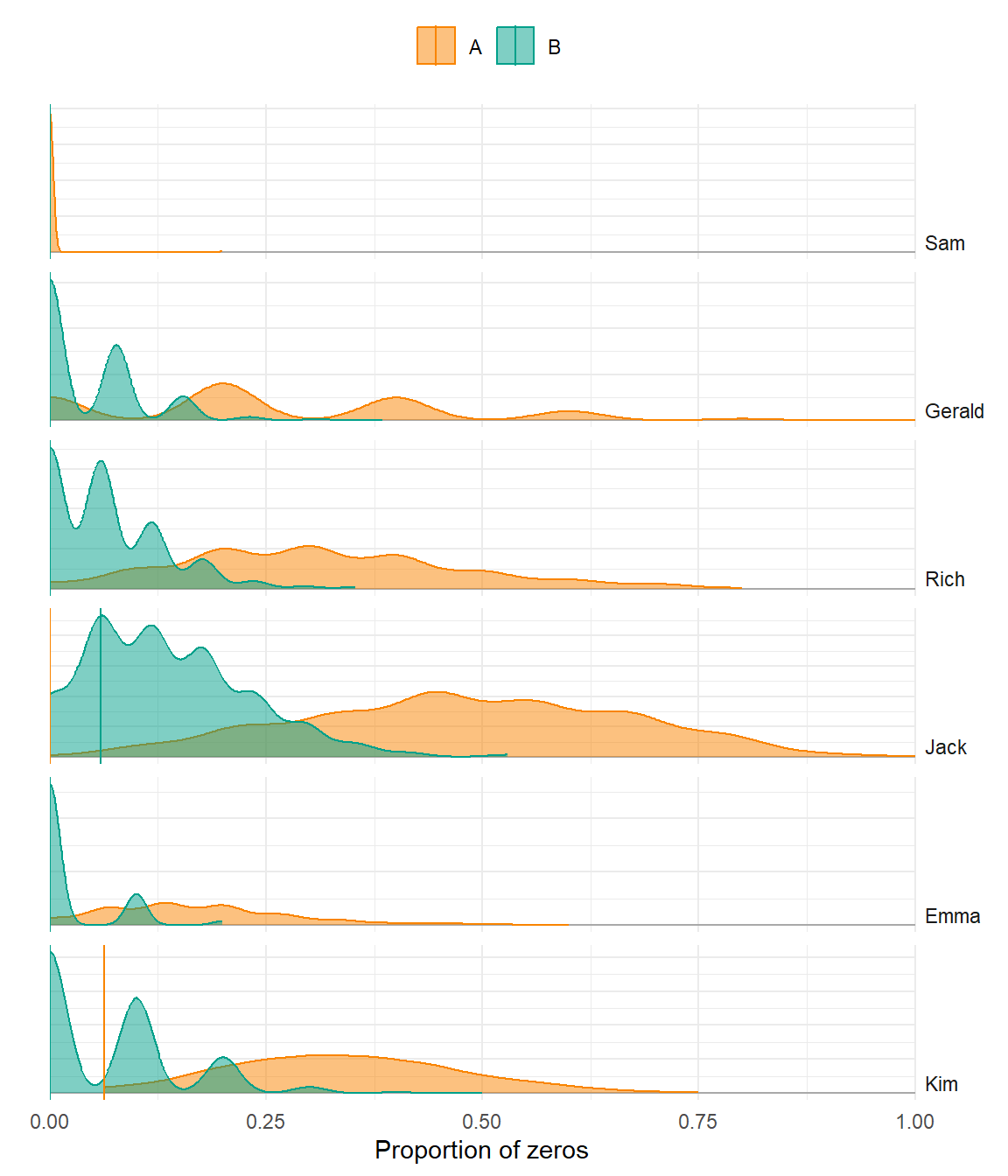
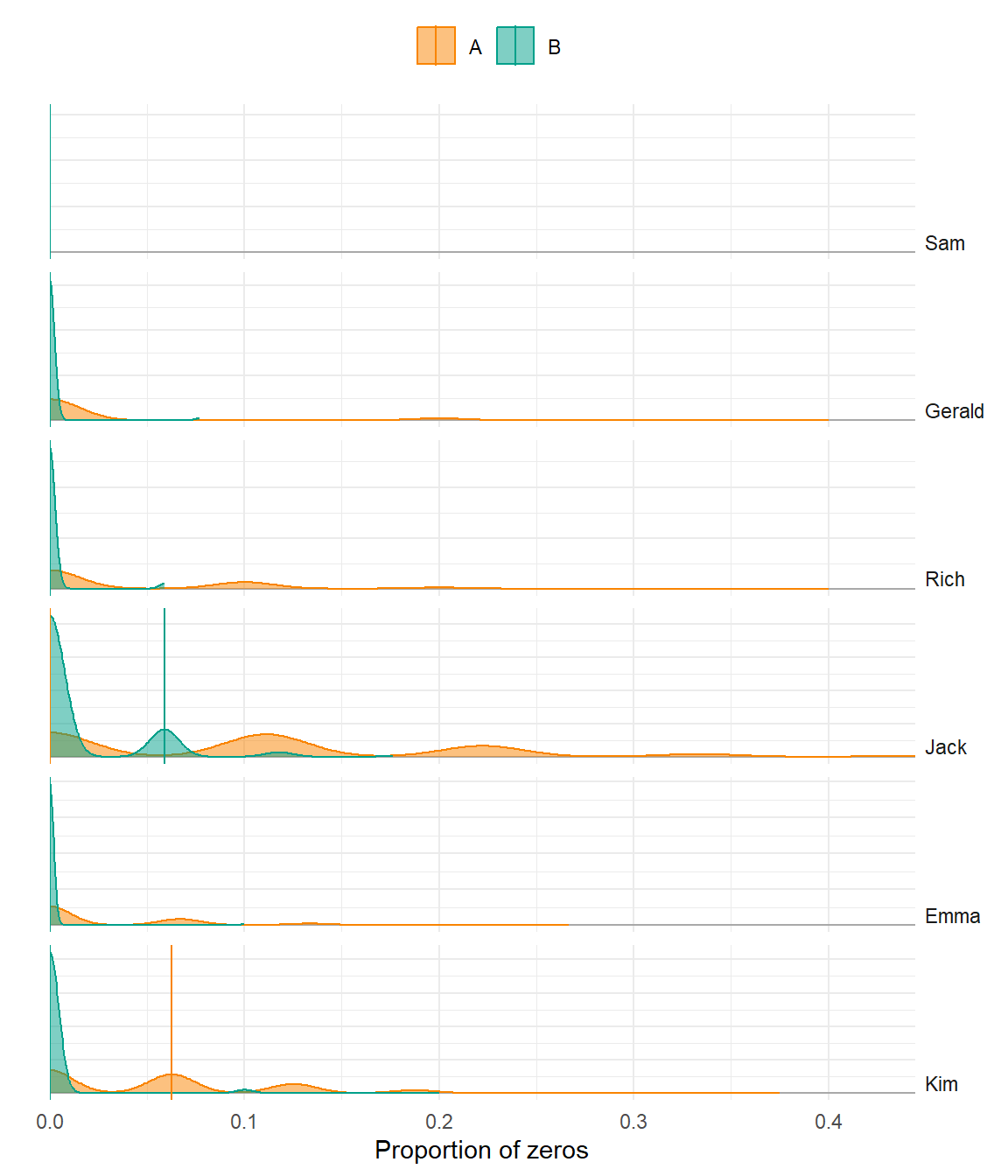
Percentage of Zeros
Poor model
Better model
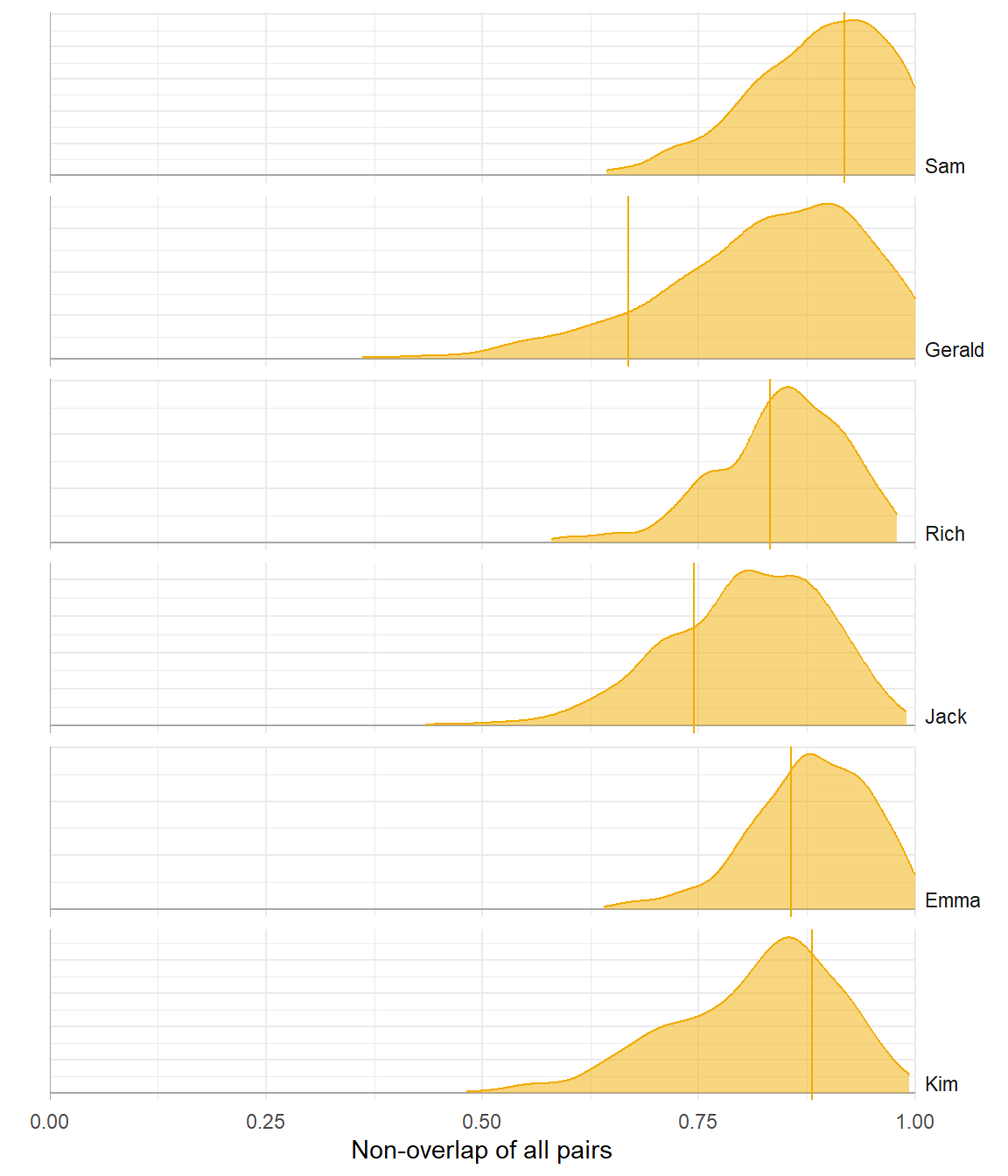
(Non-)Overlap
Poor model
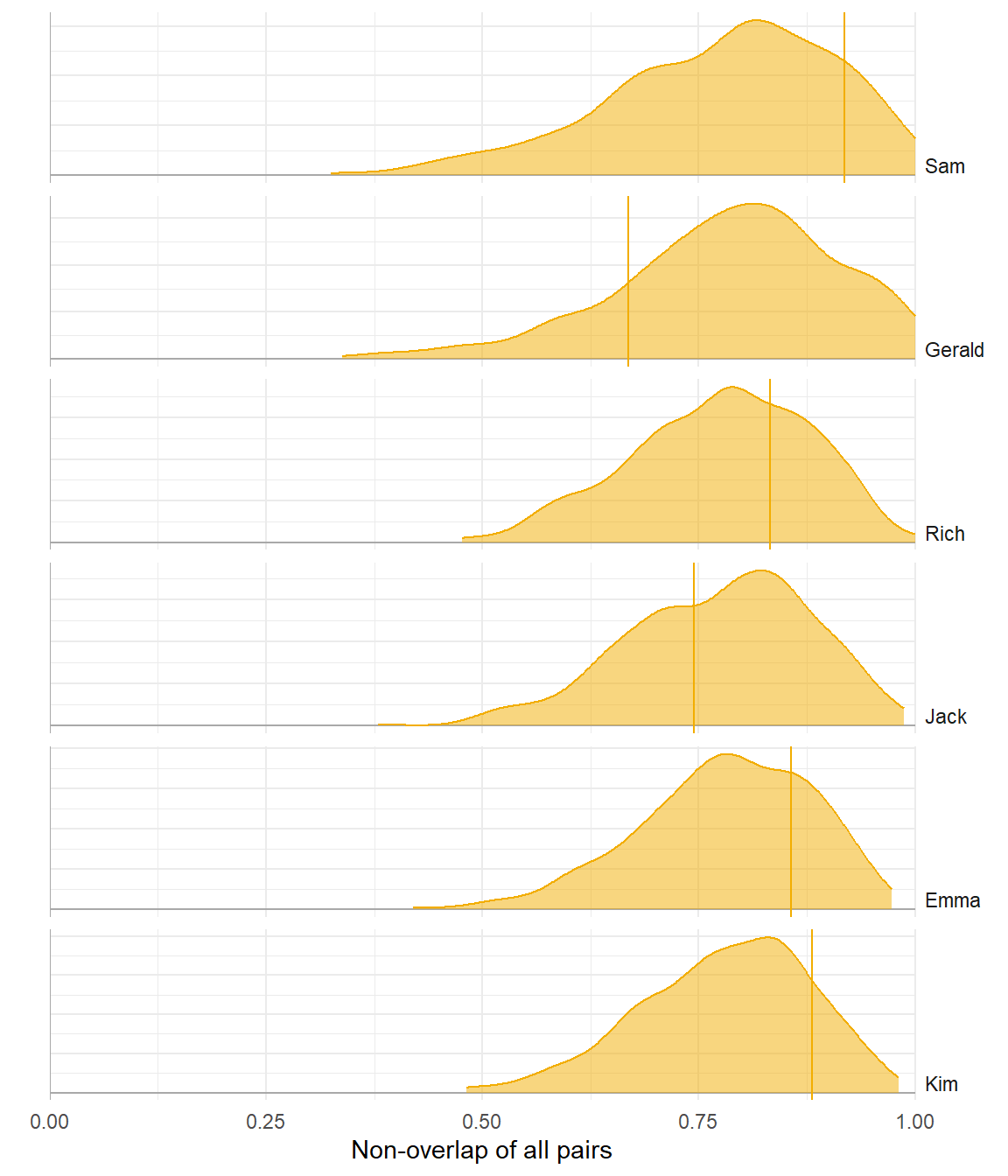
Better model
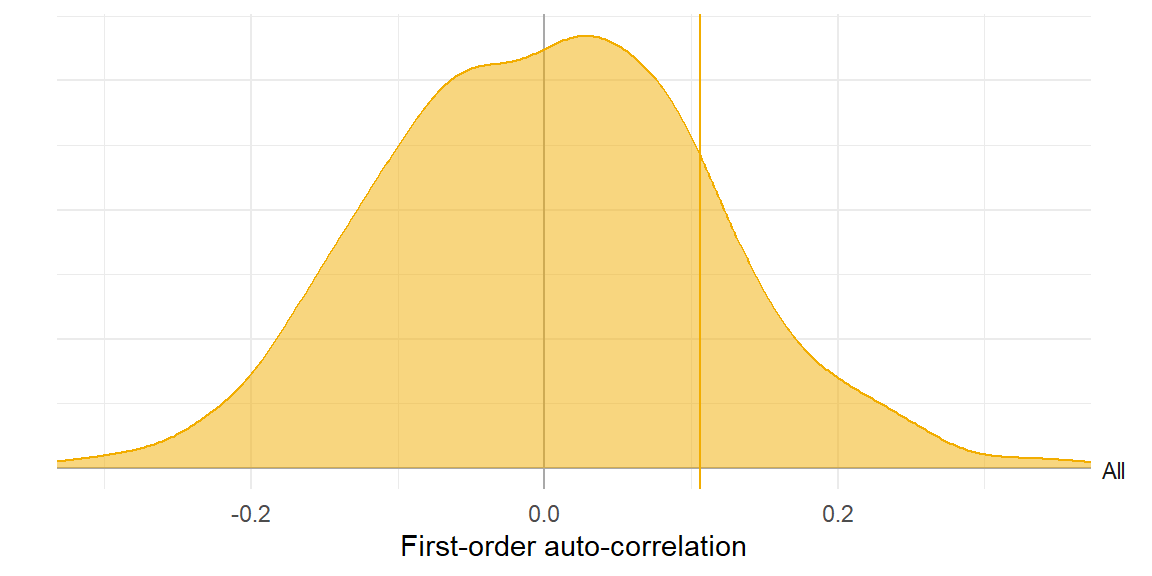
Auto-correlation
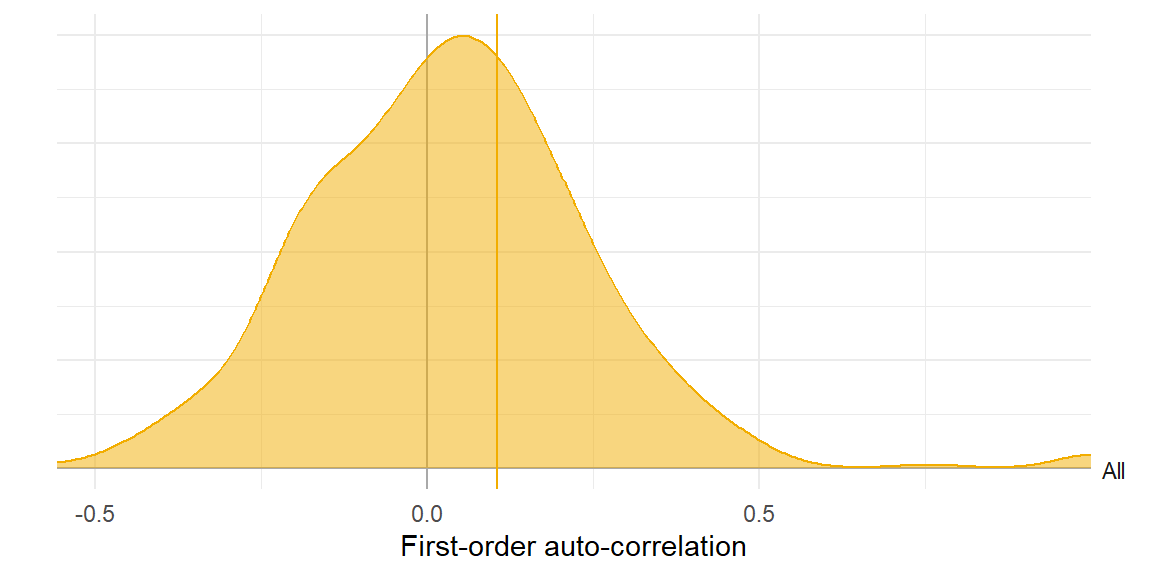
Poor model
Better model
Baseline summary statistics for new participants
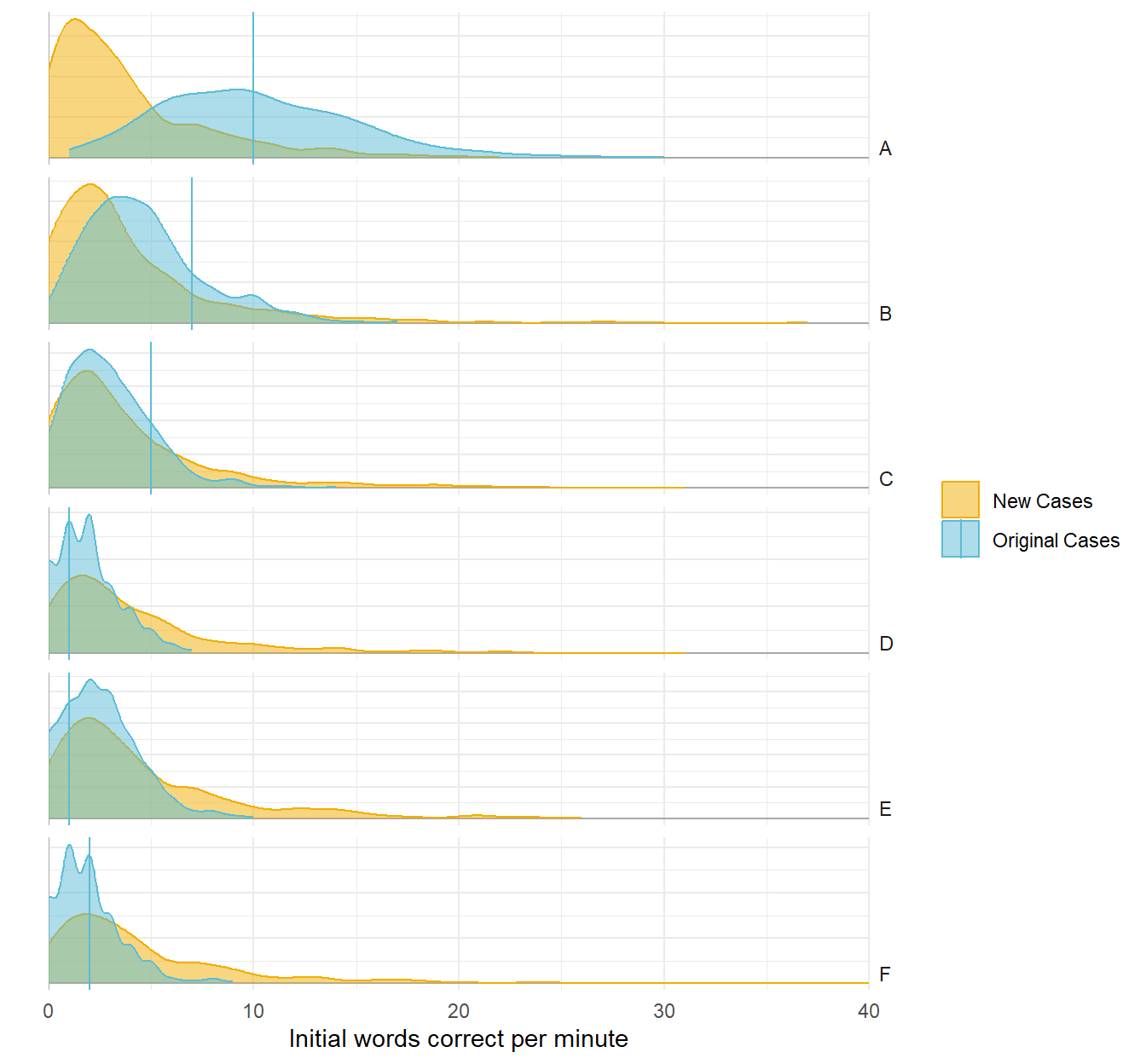
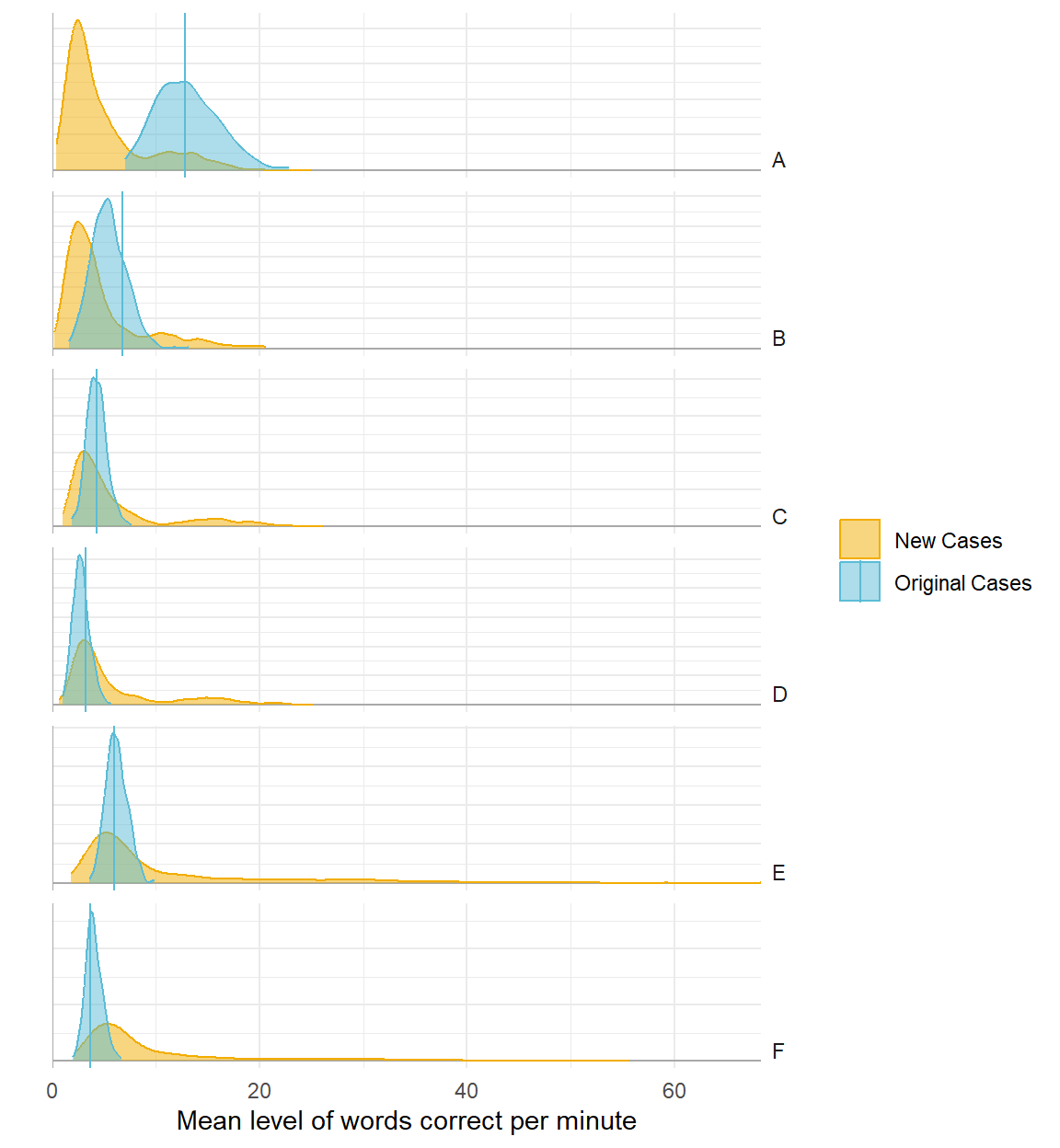
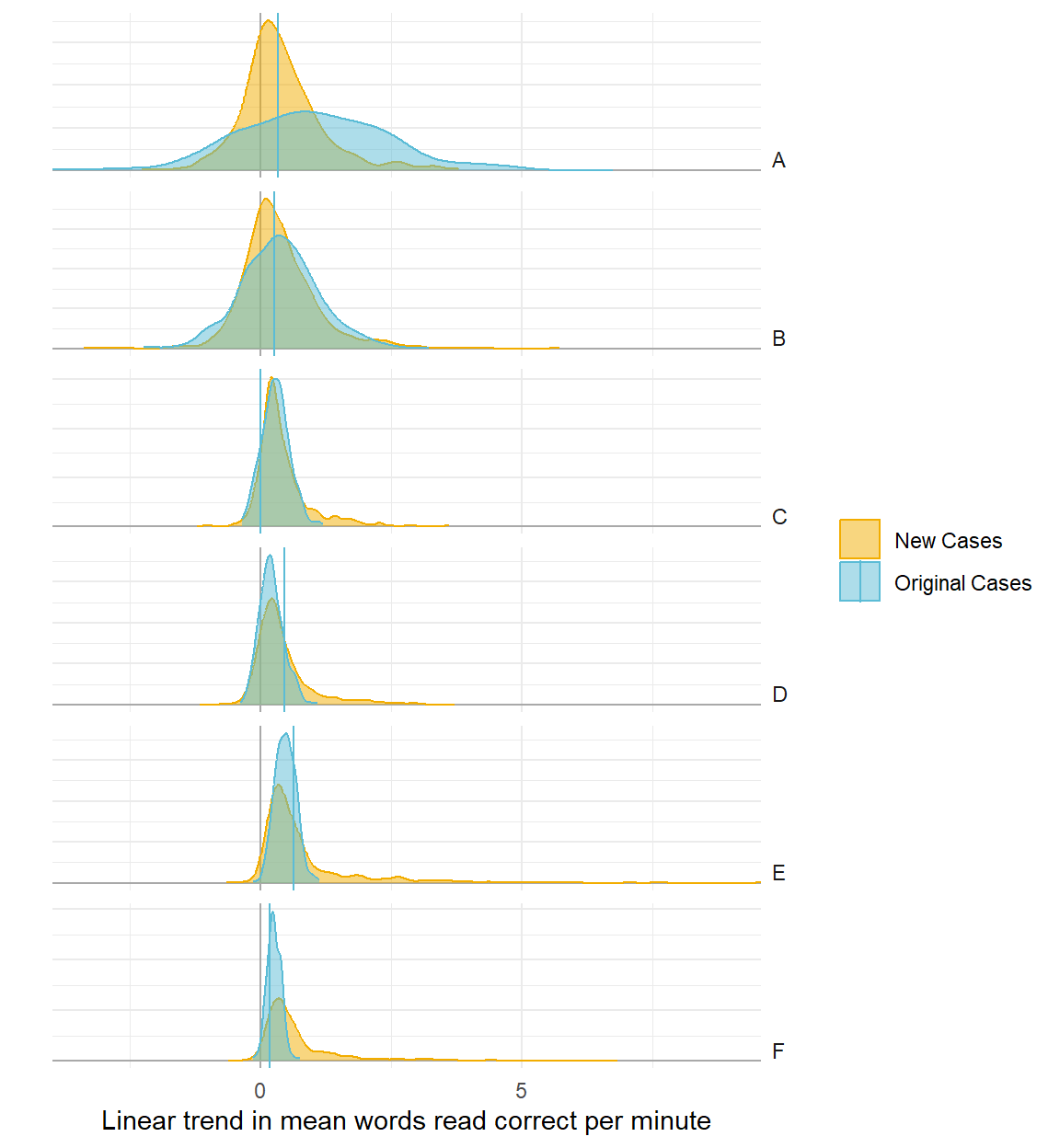
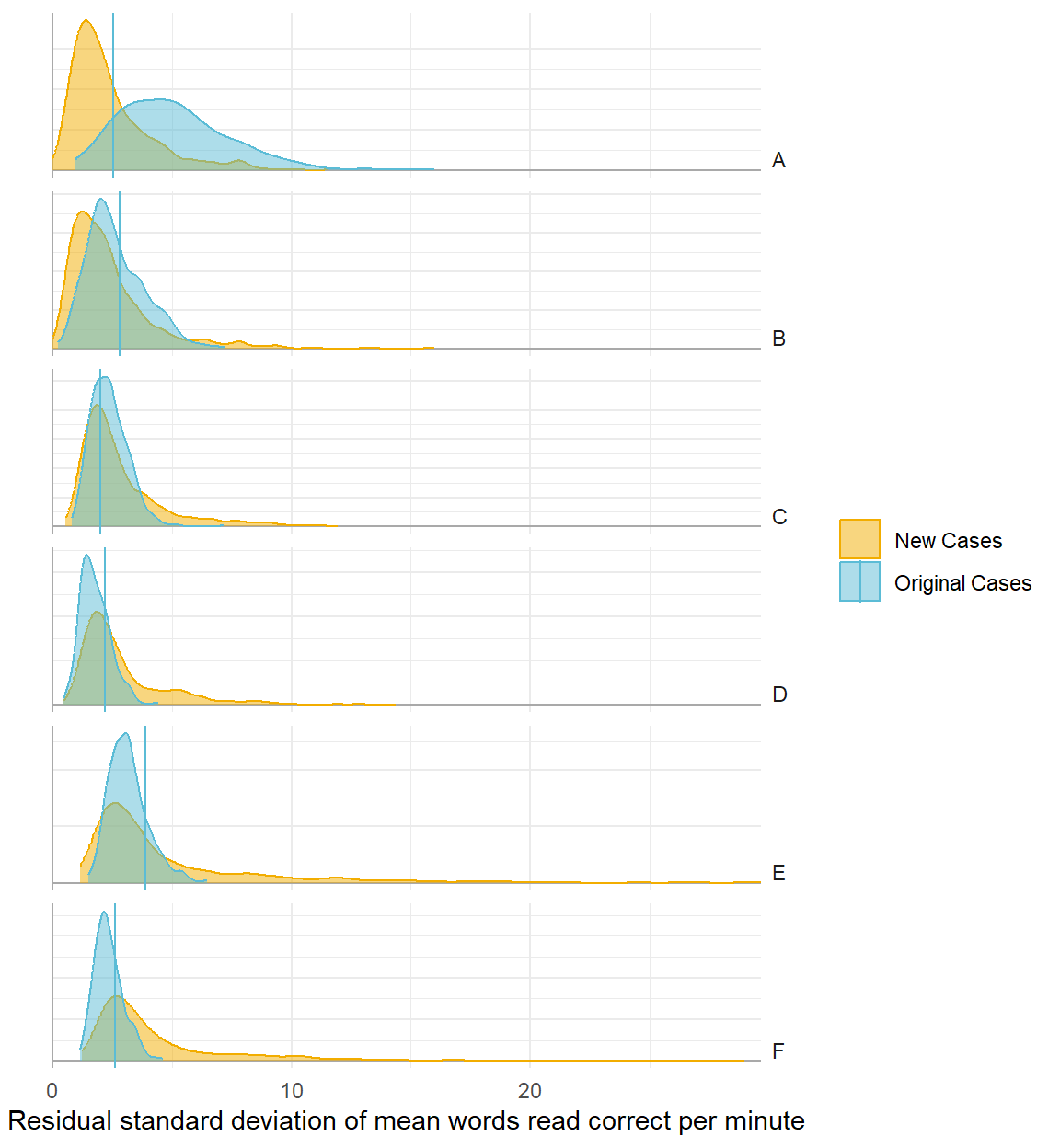
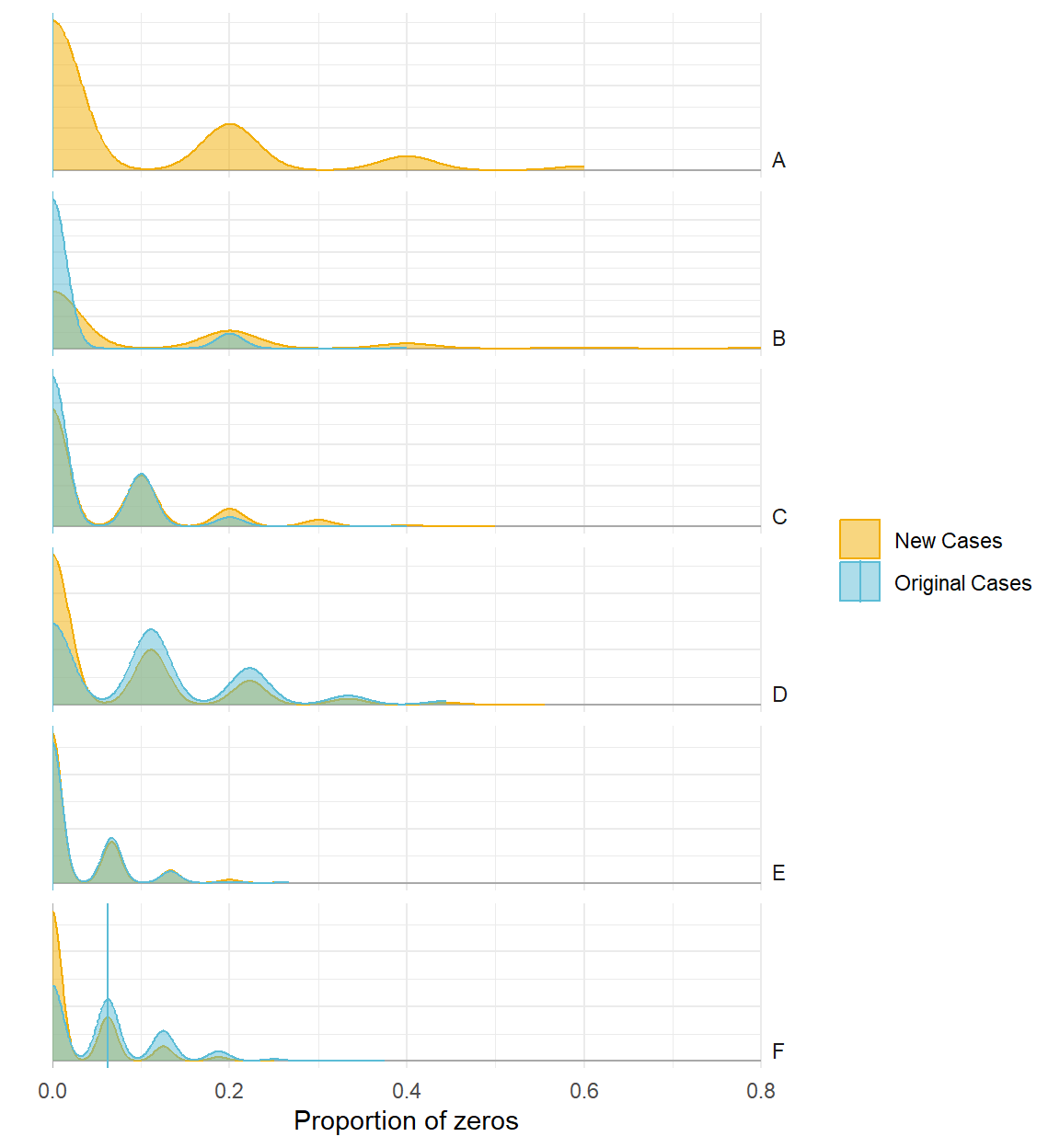
Counterfactual/hypothetical predictions
- Predictive checks can be generated for hypothetical scenarios such as different study designs with different numbers of participants.